

 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Blind XPath Injection: Booleanización [I de III]
***************************************************************************************
- Blind XPath Injection: Booleanización [I de III]
- Blind XPath Injection: Booleanización [II de III]
- Blind XPath Injection: Booleanización [III de III]
***************************************************************************************
Los ataques Blind XPath Injection han sido estudiado desde hace ya más de 6 años pero sin embargo existen aún muchos pequeños detalles sin documentar de estas técnicas de inyección. Esta serie de posts se va a centrar en el proceso de booleanización de valores descrito por Amit Kelein en los documentos que se citaron en el post de Blind XPath: Una Introducción para después evaluar algunas posibles optimizaciones computacionales al algoritmo.
Booleanización
Un proceso de booleanización consiste en descomponer un dato complejo, como por ejemplo una cadena de caracteres o un número, en una sucesión de preguntas con respuestas booleanas, es decir, de True o False. Para la extracción de un documento XML es necesario idear un método para booleanizar valores numéricos y otro para booleanizar valores de tipo texto.
Aunque el formato XPath 2.0 permite validar tipos de datos contra un esquema XML, toda la lógica de extracción descrita por Amit Klein con XPath 1.0 funciona de igual forma ya que el tipado de datos se realiza a posteriori para permitir un acceso más cómodo y no para restringir el sistema de acceso utilizado en XPath 1.0. Si bien es cierto, existen pequeños matices a la hora de construir las consultas que no afectan a la algorítmica de estos casos expuestos.
Booleanizazion de valores numéricos
En muchas partes del algoritmo es necesario extraer valores numéricos, por ejemplo, cuando se quiere saber el número de nodos o la longitud de una cadena. Para ello Amit Klein propone comprobar el número bit a bit con una sencilla técnica. Para ello el algoritmo trabaja con valores enteros con signo de 32 bits, aunque puede extrapolarse a cualquier longitud. Esta codificación implica que el primer bit es el signo. Así, primero se calcula si el número es positivo o negativo haciendo una comparación con cero.
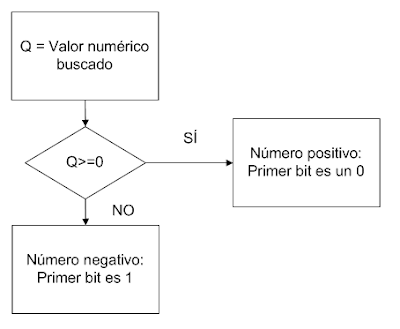
Figura 1: Comprobación de signo del valor numérico
A partir de ese momento, si el número es negativo se usará –Q en lugar de Q en el algoritmo de descubrimiento de los restantes 31 bits. Para ello se apoya en la constante N, que fucniona como una mascara y almacena el número de bits descubiertos hasta el momento. Para descubrir el siguiente bit en cada iteración se construye el número K como resultado de poner los N primeros números con su valor conocido, el bit N+1 a 1 y el resto de los bits a 0. En un determinado instante, el valor descubierto D será que se muestra en la siguiente figura:

Figura 2: Proceso de descubrimiento de bits
Como se puede ver en la tabla superior, N actúa como una máscara, así, para generar descubrir el valor de D de la posición N+1 se aplica el siguiente algoritmo.

Figura 3: Descubrimiento del valor de 1 bit
Al final, repitiendo este proceso, será posible obtener un valor numérico mediante un proceso de booleanización con técnicas Blind XPath Injection. El algoritmo completo descrito es el siguiente:

Figura 4: Algoritmo de booleanización de valores numéricos
Booleanización de valores alfanuméricos
Para poder optimizar el tiempo de acceso Amit Klein propuso un ingenioso método para extraer los valores de una cadena mediante un proceso de búsqueda binaria, ya que no existe la posibilidad de utilizar una función similar a la función ASCII() en el lenguaje SQL que convierte un carácter en un valor numérico comparable. El proceso es el siguiente:
- Calcular la longitud de la cadena S con (string-length(S)): Esta es una consulta numérica que deberá ser calculada tal y como se explica en el proceso anterior.
- Seleccionar el carácter B de la posición N como (substring(S,N,1))
Una vez seleccionado C hay que sacar su valor ASCII, para ello, se propone:
Seleccionar los caracteres imprimibles de la tabla ASCII más lo caracteres especiales de puntuación CR, LF y HT. Esto generaría un total de 97 caracteres que se incluirían en una lista L de 97 posiciones que irían de la L(0) hasta L(96).
Para poder implementar una búsqueda binaria en cada paso se utilizan las listas L1 y L2 de longitud (L/2) que tiene la primera mitad de la lista L y la segunda mitad de la lista L respectivamente. Además, se crea la lista Cn de longitud L/2 y con todos los valores de la lista valores 1.
Si el carácter B buscado está entre los caracteres de L1, entonces se cumple que:
(number(translate(B,”L1”,”Cn”))=1)
Para entender el funcionamiento del algoritmo hay que conocer que la función translate busca la cadena B dentro de la cadena L1. Si la cadena B está contenida dentro la cadena L1, entonces, devuelve el valor de Cn situado en la posición en que se encontró B dentro de L1. Al ser todos los valores de Cn “1”. En el momento en que esté contenido devolverá un valor 1. El algoritmo se podrá repetir haciendo que L sea igual a L1.
Este algoritmo tiene el problema con el valor comillas dobles “ que al ser especial haría fallar el método, por lo que previamente se comprueba si es o no ese valor. El siguiente diagrama describe el funcionamiento del algoritmo:

Figura 5: Algoritmo de booleanización de cadenas
***************************************************************************************
- Blind XPath Injection: Booleanización [I de III]
- Blind XPath Injection: Booleanización [II de III]
- Blind XPath Injection: Booleanización [III de III]
***************************************************************************************
- Blind XPath Injection: Booleanización [I de III]
- Blind XPath Injection: Booleanización [II de III]
- Blind XPath Injection: Booleanización [III de III]
***************************************************************************************
Los ataques Blind XPath Injection han sido estudiado desde hace ya más de 6 años pero sin embargo existen aún muchos pequeños detalles sin documentar de estas técnicas de inyección. Esta serie de posts se va a centrar en el proceso de booleanización de valores descrito por Amit Kelein en los documentos que se citaron en el post de Blind XPath: Una Introducción para después evaluar algunas posibles optimizaciones computacionales al algoritmo.
Booleanización
Un proceso de booleanización consiste en descomponer un dato complejo, como por ejemplo una cadena de caracteres o un número, en una sucesión de preguntas con respuestas booleanas, es decir, de True o False. Para la extracción de un documento XML es necesario idear un método para booleanizar valores numéricos y otro para booleanizar valores de tipo texto.
Aunque el formato XPath 2.0 permite validar tipos de datos contra un esquema XML, toda la lógica de extracción descrita por Amit Klein con XPath 1.0 funciona de igual forma ya que el tipado de datos se realiza a posteriori para permitir un acceso más cómodo y no para restringir el sistema de acceso utilizado en XPath 1.0. Si bien es cierto, existen pequeños matices a la hora de construir las consultas que no afectan a la algorítmica de estos casos expuestos.
Booleanizazion de valores numéricos
En muchas partes del algoritmo es necesario extraer valores numéricos, por ejemplo, cuando se quiere saber el número de nodos o la longitud de una cadena. Para ello Amit Klein propone comprobar el número bit a bit con una sencilla técnica. Para ello el algoritmo trabaja con valores enteros con signo de 32 bits, aunque puede extrapolarse a cualquier longitud. Esta codificación implica que el primer bit es el signo. Así, primero se calcula si el número es positivo o negativo haciendo una comparación con cero.

Figura 1: Comprobación de signo del valor numérico
A partir de ese momento, si el número es negativo se usará –Q en lugar de Q en el algoritmo de descubrimiento de los restantes 31 bits. Para ello se apoya en la constante N, que fucniona como una mascara y almacena el número de bits descubiertos hasta el momento. Para descubrir el siguiente bit en cada iteración se construye el número K como resultado de poner los N primeros números con su valor conocido, el bit N+1 a 1 y el resto de los bits a 0. En un determinado instante, el valor descubierto D será que se muestra en la siguiente figura:

Figura 2: Proceso de descubrimiento de bits
Como se puede ver en la tabla superior, N actúa como una máscara, así, para generar descubrir el valor de D de la posición N+1 se aplica el siguiente algoritmo.

Figura 3: Descubrimiento del valor de 1 bit
Al final, repitiendo este proceso, será posible obtener un valor numérico mediante un proceso de booleanización con técnicas Blind XPath Injection. El algoritmo completo descrito es el siguiente:

Figura 4: Algoritmo de booleanización de valores numéricos
Booleanización de valores alfanuméricos
Para poder optimizar el tiempo de acceso Amit Klein propuso un ingenioso método para extraer los valores de una cadena mediante un proceso de búsqueda binaria, ya que no existe la posibilidad de utilizar una función similar a la función ASCII() en el lenguaje SQL que convierte un carácter en un valor numérico comparable. El proceso es el siguiente:
- Calcular la longitud de la cadena S con (string-length(S)): Esta es una consulta numérica que deberá ser calculada tal y como se explica en el proceso anterior.
- Seleccionar el carácter B de la posición N como (substring(S,N,1))
Una vez seleccionado C hay que sacar su valor ASCII, para ello, se propone:
Seleccionar los caracteres imprimibles de la tabla ASCII más lo caracteres especiales de puntuación CR, LF y HT. Esto generaría un total de 97 caracteres que se incluirían en una lista L de 97 posiciones que irían de la L(0) hasta L(96).
Para poder implementar una búsqueda binaria en cada paso se utilizan las listas L1 y L2 de longitud (L/2) que tiene la primera mitad de la lista L y la segunda mitad de la lista L respectivamente. Además, se crea la lista Cn de longitud L/2 y con todos los valores de la lista valores 1.
Si el carácter B buscado está entre los caracteres de L1, entonces se cumple que:
(number(translate(B,”L1”,”Cn”))=1)
Para entender el funcionamiento del algoritmo hay que conocer que la función translate busca la cadena B dentro de la cadena L1. Si la cadena B está contenida dentro la cadena L1, entonces, devuelve el valor de Cn situado en la posición en que se encontró B dentro de L1. Al ser todos los valores de Cn “1”. En el momento en que esté contenido devolverá un valor 1. El algoritmo se podrá repetir haciendo que L sea igual a L1.
Este algoritmo tiene el problema con el valor comillas dobles “ que al ser especial haría fallar el método, por lo que previamente se comprueba si es o no ese valor. El siguiente diagrama describe el funcionamiento del algoritmo:

Figura 5: Algoritmo de booleanización de cadenas
***************************************************************************************
- Blind XPath Injection: Booleanización [I de III]
- Blind XPath Injection: Booleanización [II de III]
- Blind XPath Injection: Booleanización [III de III]
***************************************************************************************














2 comentarios:
Que buen post! Ya extrañaba uno de estos.
Estamos esperando las continuaciones.
Buen post. Me trae a la memoria cierto reto hacking.
Una pregunta: ¿alguna vez se te ha ocurrido experimentar con Sharepoint y tratar de conseguir una CAML injection? Por los ejemplos de código que he podido ver en aplicaciones para MOSS o WSS, abunda la práctica de montar queries CAML dinámicas contra listas o bibliotecas de documentos. Es sólo una idea...
Saludos
Publicar un comentario