Wetransfer es un servicio en
Internet que permite enviar ficheros de gran tamaño sin la necesidad de darse de alta en el servicio o instalar una aplicación. En su versión gratuita permite transferir un máximo de
2 GB de información en forma de ficheros adjuntos junto a un breve mensaje para el destinatario de un mensaje de correo electrónico.
 |
| Figura 1: Cómo saber quién y para qué ha utilizado We Transfer |
El servicio permite enviar la información adjunta a un correo electrónico de la persona destinataria o generar un enlace de descarga para enviarlo a una o más direcciones de correo electrónico, o simplemente tener ese contenido en el servidor del servicio para descargarlo cuando sea necesario. Eso sí, el contenido tiene un tiempo de vida máximo de
7 días, momento a partir del cual el contenido es eliminado y deja de estar disponible.
 |
| Figura 2: Forma de indicar en WeTransfer el destinatario de la información adjunta |
En la siguiente
Prueba de Concepto (PoC) se mostrará cómo terceras partes podrían:
• Obtener contenido enviado por WeTransfer o almacenado en sus servidores.
• Obtener URLs y parámetros enviados por GET a través de Archive.org.
• Obtener direcciones de correo de los destinatarios de los contenidos junto a sus mensajes.
• Obtener nombres de usuarios bajo ciertos nombres de dominio.
1.- Obtener contenido enviado por WeTransfer o almacenado en sus servidores
Como se ha comentado, la información que se envía adjunta por
WeTransfer tiene un tiempo de vida de
7 días, momento en el cual desaparece de sus servidores.
Una primera aproximación se basa en comprobar la existencia del fichero
robots.txt y ver qué rutas no quiere el servicio que sean indexadas por los motores de búsqueda.
 |
| Figura 3: Fichero robots.txt de wetransfer.com |
Si hacemos un poco de
hacking con buscadores para ver si las
opciones de indexación de la web son correctas, y preguntamos a
Google qué contenidos tiene indexados referentes a la
URL downloads observamos cómo únicamente devuelve un resultado, pero permite repetir la búsqueda e incluir los resultados que han sido omitidos.
 |
| Figura 4: Resultados devueltos inicialmente por Google |
De esta forma, pasamos inicialmente de 1 resultado a 15000 resultados aproximadamente.
 |
| Figura 5: Resultados omitidos por Google en la primera consulta |
Aquí he de indicar que no todas las
URLs devueltas por
Google permiten la descarga de contenido, pero algunas de ellas sí, y es posible acceder a este contenido si aún no ha caducado buscando la
URL adecuada.
 |
| Figura 6: Descarga de un fichero ZIP - y su contenido - con fotografías indexado por Google |
Se observa cómo es posible, en este ejemplo, acceder a más de
25MB de fotografías enviadas por
WeTransfer, aunque no es posible conocer quién es el emisor y/o destinatarios de las mismas - sin utilizar servicios de terceros -, pero en ellas aparecen rostros de personas que puede que no hayan dado permiso para estar presentes en
Internet.
2.- Obtener URLs y parámetros enviados por GET a través de Archive.org
Lo realizado en el punto anterior me parecía el “
método clásico” de comprobar si cierto contenido era accesible a través de los buscadores, así que decidí enfocarlo desde otra manera para intentar que fuera algo más original. Para ello pensé en analizar las peticiones realizadas al servidor en el envío de la información adjunta para intentar obtener parámetros enviados por
GET o
POST, y a partir de ahí intentar obtener información un poco más sensible.
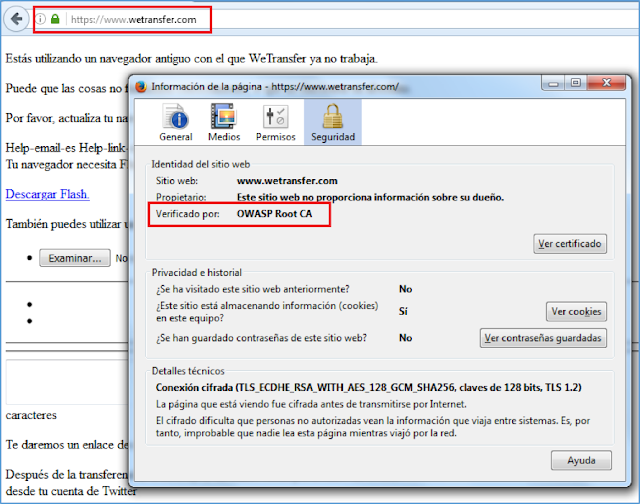 |
| Figura 7: Ruptura de la cadena de certificación SSL a través de ZAP Proxy |
Lo primero fue intentar capturar en el momento de envío de información adjunta las peticiones
HTTP/HTTPS con
ZAP y
Burp Suite y no obtuve ningún resultado, ya que como se ve en la siguiente figura, la página no es capaz de cargarse de manera correcta al reenviar las peticiones
HTTP/S a
ZAP. Con
Burp Suite los resultados fueron idénticos a los anteriores:
 |
| Figura 8: Ruptura de la cadena de certificación SSL a través de Burp Suite |
A partir de aquí decidí consultar, sacando partido a las
opciones que tiene Archive.org para hacer hacking, qué
URLs bajo en nombre de dominio
wetransfer.com habían sido capturadas por
archive.org. En total,
2404 URLs.
 |
| Figura 9: URLs capturadas por archive.org |
Pueden observase parámetros enviados por
GET, como la dirección de correo de un destinatario de información enviada por
WeTransfer.
A partir de este momento, ya es muy sencillo buscar direcciones de correo electrónico de destinatarios de información, incluso los mensajes que le han sido enviados y nombres de usuarios bajo ciertos nombres de dominio.
3.- Obtener direcciones de correo de los destinatarios de los contenidos junto a sus mensajes
Llegados a este punto, es trivial extraer direcciones de correos de destinatarios de mensajes. Para ello únicamente habría que hacer búsquedas dentro de archive.org con patrones como
to=, @gmail, %40, etcétera.
 |
| Figura 10: Direcciones de correo electrónico extraídas con el patrón "to=" |
 |
| Figura 11: Cuentas de correo electrónico extraídas con el patrón "@gmail" |
Para la obtención del mensaje enviado a una cuenta de correo electrónico, podría utilizarse el patrón
msg=:
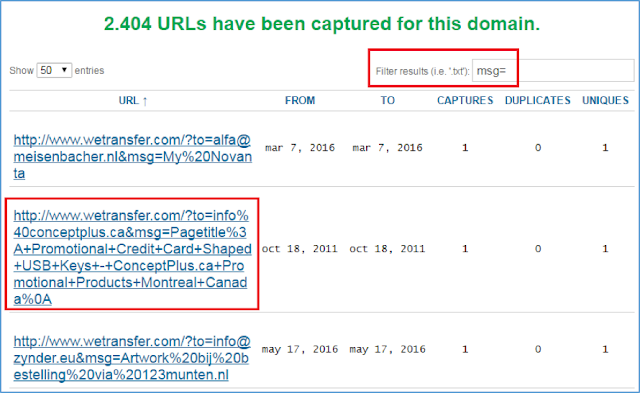 |
| Figura 12: Mensaje enviado junto con la cuenta de correo electrónico del destinatario |
4.- Obtener nombres de usuarios bajo ciertos nombres de dominio
Para terminar, si queremos buscar, por ejemplo, si existe algún
username con valor
"admin" bajo un nombre de dominio, podemos utilizar el patrón
admin@
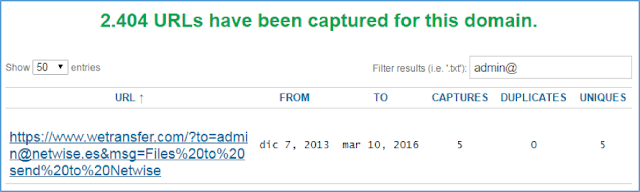 |
| Figura 13: Envío hacia el usuario admin@netwise.es |
Pero esto se puede hacer con cualquier nombre de usuario del dominio y buscar si ha habido, por ejemplo alguna filtración hacia un determinado destinatario.
Conclusiones Finales
Como se ha visto, es posible acceder a información que aún no haya sido eliminada del todo en
WeTransfer haciendo un poco de
hacking con buscadores, así que no es una buena idea mandar información que pudiera llegar a comprometerte si cae en manos de un cibercriminal.
Tampoco utilices cuentas de correo de carácter corporativo para enviar información utilizando este servicio, ya que como se ha visto es posible conocer usuarios que están bajo ese nombre de dominio y puede que a veces coincida con el nombre de usuarios de servicios como
Apache,
FTP, SSH, etc. Además, no es una buena idea tener cuentas de correo corporativas del tipo admin@, ya que da una idea de cuál es el nivel de madurez en seguridad informática con el que cuenta esa organización.
Autor: Amador Aparicio de la Fuente (@amadapa)





 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 


























2 comentarios:
Buen artículo, Amador.
Muy interesante. Da una visión de cómo poder utilizar este servicio... No utilizarlo.
Gran trabajo.
David, que un servicio sea público no significa que no pueda ser utilizado, sencillamente tienes que tener conciencia que todo lo que envies quedará disponible en internet. Por ejemplo, puede ser un video de una presentación que por su tamaño no es posible utilizar un servicio tradicional como correo electrónico.
Si lo que deseas enviar información sensible, puedes utilizar servidores privados y algún método de cifrado.
Un saludo!!
Publicar un comentario