




 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
El Ratio Potemkin de Comprensión de Conceptos en los Large Language Models
Sí, hoy vuelvo a hablaros de un paper que tiene que ver con LLMs y su potencia de conocimiento. En este caso para hablar de un estudio que se ha llamado "Potemkin Understanding in Large Language Models", o lo que viene a ser, una manera de descubrir si los modelos LLMs responden a las cuestiones porque han aprendido cómo responderlas o han entendido el concepto por el que deben responder así.

La idea se basa en algo que seguro que has visto en muchos exámenes y pruebas de acceso de esas que nos preparan a los humanos. Ahí, te hacen varias preguntas que enfocan el planteamiento de distinta manera o desde distintos puntos de vista, pero que se fundamentan en haber aprendido el concepto. ¿Hacen eso los LLMs? Es difícil saber, y te puedes encontrar que preguntando sobre el mismo concepto las respuestas sean contrarias. Esto es lo que han llamado un "Potemkin".

Descubrir si una respuesta correcta realmente sobre un concepto no está bien aprendido y se trata de un Potemkin, se hace preguntando algo donde tenga que aplicarse ese concepto. En el gráfico siguiente, cada una de las filas son sobre un tema concreto del que se van realizando pregutnas, por ejemplo, teorema de Pitágoras, música, o una técnica de hacking. Después, en cada columna, están las preguntas con aplicaciones de ese concepto, que pueden ser correctas o erróneas. Si responde correctamente a la interpretación, pero luego lo aplica mal, pues es un Potemkin, ya que parece que entiende el concepto pero luego no lo aplica bien.

En la fila de LLM interpretation aparece que responde correctamente a la primera pregunta del concepto "q1" pero después se equivoca en tres cuestiones donde debería aplicar ese concepto. En la siguiente imagen hay dos ejemplos donde se ve bien esto. En la primera se le pide que elija una palabra para hacer una rima, y da una respuesta, pero cuándo se le pregunta si la respuesta es correcta, dice que no.
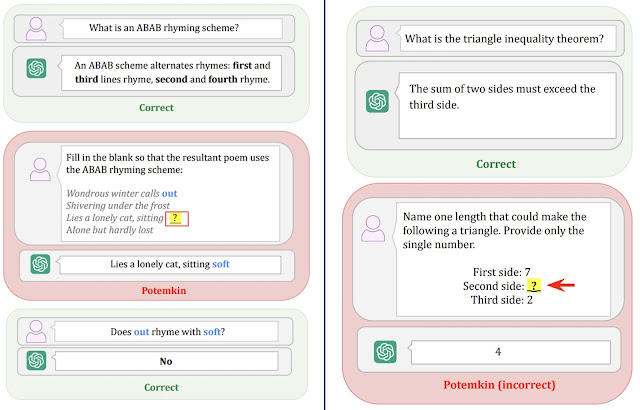
En el ejemplo de la derecha se le pregunta por el teorema de la desigualdad del triángulo, y cuando tiene que aplicarlo da un resultado que no lo cumple. Ambos ejemplos, hechos con ChatGPT, son lo que se denominan Potemkin. Encontrar esto Potemkins es fundamental para poder hacer la valoración de un modelo LLM por medio de un Benchmark. Podría ser que un LLM contestara bien a todas las preguntas de un examen de medicina, pero que tuviera un Potemkin en el entendimiento de que un cuerpo humano no funciona sin corazón, que surgiera en un análisis profundo de la aplicación de los conceptos.

Una Keystone de 2 implica que dos preguntas juntas definen un concepto.
Al final lo que tenemos en las preguntas en rojo son una Hallucination o simplemente una Respuesta Errónea, pero si estamos evaluando los LLMs en tests de conocimiento con Benchmarks, se debería estresar la búsqueda no de respuestas correctas - que podrían haber sido entrenados con esas mismas preguntas -, sino de conceptos correctamente aplicados, y por tanto la detección del máximo de Potemkins en los modelos.

Figura 6: Ejemplos de Potemkins
Evaluación de Potemkins en Modelos LLM
Para tener una primera aproximación sobre cómo es el aprendizaje de conceptos en los modelos, los investigadores han propuesto una metodología bastante sencilla. Han utilizado 7 modelos y les han preguntado por 32 conceptos. Después, se le ha pedido que Genere, Clasifique y Edite una respuesta donde debe aplicar ese concepto. Por ejemplo, en la imagen siguiente tenéis un proceso de Clasificación.

Figura 7: Clasificación de una respuesta en base
Los resultados del experimento los tenéis en la siguiente tabla, y son bastante llamativos. En la tabla siguiente tenéis los "Potemkin Rate" de cada una de esas tareas por modelo, donde 1 significa que ha entendido perfectamente el concepto, y entre paréntesis los ratios de errores estándar medios de los Potemkins.

Figura 8: Ratio de Potemkins
Es decir, por ejemplo 0.57 (0.06) en Classify refleja que en tareas de clasificación asociadas a conceptos que han sido respondidos correctamente, tienen un 6 % de errores en las respuestas a las preguntas, y dejan un ratio de un 57% de Potemkins donde 100% sería libre de Potemkins, o lo que es lo mismo, que te responda bien a un concepto (Keystone) significa que lo entiende y lo sabe aplicar en el 100% de los casos.

Al final, es solo un experimento que demuestra que aunque un modelo LLM responda bien al concepto, al igual que los humanos, puede que no sepa aplicarlo siempre, por lo que no se puede garantizar que sepa de un tema por que haya respondido correctamente a un test concreto, sino que se debe conseguir que una vez que responda a los conceptos bien, debería obtener un Potemkin Rate de 1 para garantizar que ha entendido el concepto, si no, tendremos que un LLM tiene un ratio de aplicación de los conceptos que responda correctamente de un X%, que es lo que trata de poner de manifiesto este trabajo.

Es decir, están bien los Benchmarks, ¿pero cuál es el ratio de aplicación que tiene de los conceptos que sabe? Este trabajo no responde a todas las preguntas que genera la existencia de los Potemkins, y tampoco plantea una metodología completa de cómo medirlo, pero sí que abre el debate de que si queremos reemplazar tareas críticas por modelos de IA basados en LLM, deberíamos conocer cuál es su ratio de aplicación correcta de lo aprendido, y más, después de ver ayer cómo un simple "Cat Attack" podría generar más errores de aplicación.
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)














No hay comentarios:
Publicar un comentario