





 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Hacking driven by Robots.txt
El fichero Robots.txt es uno de los más incomprendidos por todo el mundo. A pesar de su aparente simpleza, cada uno lo escribe como le da la gana sin entender que no es un standard, y que cada buscador lo implementa como quiere, y que es muy sencillo de saltárselo. Ya, hace tiempo le dedique un periodo a juguetear con él y darme cuenta de que esos ficheros eran unos incomprendidos.
Sin embargo, hay que decirlo, para el mundo del hacking puede ser una fuente inagotable de conocimiento, no solo porque sea un sitio chulo para firmar un hackeo, sino porque además te puede dirigir totalmente el ataque. Este es el robots.txt de RTVE.es.

Figura 1: Robots.txt de RTVE.es
Como podéis ver, en este fichero se ha probido la indexación de ficheros *.flv *.mp3 y *.inc, o eso al menos es lo que cree el administrador del sitio web, porque como se puede ver, podemos hacer las pertinentes búsquedas en Google para ver si le ha hecho algún caso o ha pasado de él en cano.

Figura 2: Ficheros FLV
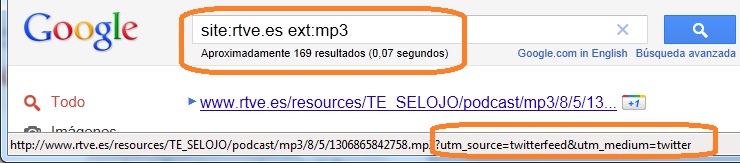
Figura 3: Ficheros mp3

Figura 4: Fichero inc
Como se puede observar Google pasa de lo que le cuentes, e indexa los ficheros que el administrador cree haber bloqueado. ¿Por qué? Pues porque el comodín * es muy cómodo en las consolas de los sistemas operativos, pero solo puede utilizarse en el USER-Agent de los ficheros robots.txt, es decir, no es interpretado. Es por ello que el administrador, mientras piensa que ha bloqueado esos ficheros, lo que ha hecho ha sido dirigir las miradas de los más curiosos.
Otra de las cosas divertidas son los directorios. Esto si es parte del formato más común de los ficheros robots.txt, pero se tiene que tener en cuenta que los más curiosos van a probar todos ellos. Sobre este hecho, hace tiempo escribimos un artículo en el que recomendabamos que esa carpeta no debería mostrar ningún dato, es decir, que por defecto devolviera una página vacía, así no se da ninguna información extra. Sin embargo, si dejas como documento el menú completo de la aplicación vas a darle las llaves de acceso a mucha información a un posible atacante.

Figura 5: Menú de aplicación
Además, tampoco es santo de mi devoción solo proteger el menú, ya que si alguien consigue una password ya tiene donde usarla. Mejor que no vea ni la puerta para que no pueda meter la llave.

Figura 6: Petición de usuario y password
Y todo esto, porque aunque se haya prohibido una ruta, como en este caso scdweb, siempre puede acabar donde no te lo esperas. Mucho cuidadito con lo que escribes en los robots.txt.
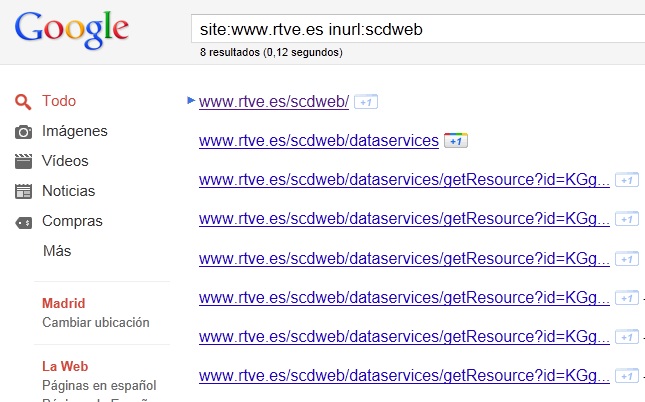
Figura 7: ruta prohibida acabando en Google
Saludos Malignos!
Sin embargo, hay que decirlo, para el mundo del hacking puede ser una fuente inagotable de conocimiento, no solo porque sea un sitio chulo para firmar un hackeo, sino porque además te puede dirigir totalmente el ataque. Este es el robots.txt de RTVE.es.
Figura 1: Robots.txt de RTVE.es
Como podéis ver, en este fichero se ha probido la indexación de ficheros *.flv *.mp3 y *.inc, o eso al menos es lo que cree el administrador del sitio web, porque como se puede ver, podemos hacer las pertinentes búsquedas en Google para ver si le ha hecho algún caso o ha pasado de él en cano.
Figura 2: Ficheros FLV
Figura 3: Ficheros mp3
Figura 4: Fichero inc
Como se puede observar Google pasa de lo que le cuentes, e indexa los ficheros que el administrador cree haber bloqueado. ¿Por qué? Pues porque el comodín * es muy cómodo en las consolas de los sistemas operativos, pero solo puede utilizarse en el USER-Agent de los ficheros robots.txt, es decir, no es interpretado. Es por ello que el administrador, mientras piensa que ha bloqueado esos ficheros, lo que ha hecho ha sido dirigir las miradas de los más curiosos.
Otra de las cosas divertidas son los directorios. Esto si es parte del formato más común de los ficheros robots.txt, pero se tiene que tener en cuenta que los más curiosos van a probar todos ellos. Sobre este hecho, hace tiempo escribimos un artículo en el que recomendabamos que esa carpeta no debería mostrar ningún dato, es decir, que por defecto devolviera una página vacía, así no se da ninguna información extra. Sin embargo, si dejas como documento el menú completo de la aplicación vas a darle las llaves de acceso a mucha información a un posible atacante.
Figura 5: Menú de aplicación
Además, tampoco es santo de mi devoción solo proteger el menú, ya que si alguien consigue una password ya tiene donde usarla. Mejor que no vea ni la puerta para que no pueda meter la llave.
Figura 6: Petición de usuario y password
Y todo esto, porque aunque se haya prohibido una ruta, como en este caso scdweb, siempre puede acabar donde no te lo esperas. Mucho cuidadito con lo que escribes en los robots.txt.
Figura 7: ruta prohibida acabando en Google
Saludos Malignos!
















10 comentarios:
devoción
Hola
y como proteges el fichero para que la información no sea visible? si haces el fichero oculto deja de funcionar la indexación de google?
Un saludo
Manuel Prado
Muy bueno. me gusta.
Para evitar que cualquier robot indexe una determinada página de su sitio, deberá insertar la metaetiqueta que le indicamos a continuación en la sección de su página:
Para que todos los robots, excepto los de Google, indexen una página determinada de su sitio:
http://www.robotstxt.org/meta.html
Saludos a todos.
No me deja meter html en el comentario, lo siento....en el anterior comentario me ha borrado código..
Muy interesante!!! :)
Casualmente relacionado con el fichero robosss.tequiste
http://community.websense.com/blogs/securitylabs/archive/2011/07/26/sex-shops-and-robot-txt-helps-to-leak-data.aspx
Para el anonimo que pregunto
(
Anónimo dijo...
Hola
y como proteges el fichero para que la información no sea visible? si haces el fichero oculto deja de funcionar la indexación de google?
Un saludo
Manuel Prado
)
Con htaccess podria ser.Y pues si bloqueas el archivo obviamente el spider no lo encontrara mas.
Aunque lo capes con el robots.txt, si una URL tiene enlaces desde otras no capadas, Google va a indexar esas URLs, otra cosa diferente es que no las va a rastrear. Incluso poniendo un enlace en Google+ hacia una URL capada mediante robots y sin enlace web convencional, también lo va a indexar.
El comportamiento de la web de RTVE es normal, para no indexar nada lo único que sirve es la meta "noindex", en el head del html o en el caso de flv, pdf, mp3 y similares, en los headers del httpd.
Un saludo
@Javier Lorente, Google se salta el comportamiento de los Robots.txt. El fichero está mal creado, no es compliance con el standar de robots.txt que tienes en el post de "Funcionamiento de los Robots" en mi blog.
Antes de meterse cualquier URL en la BBDD, por mucho que esté enlazada la URL, debe comprobarse el robots.txt del dominio, y Google la hace bastante malamente.. }:S
Saludos!
de todas formas creo que el robots dice que no indexte *.flv pero en el / por eso salen los resultados en /video y otras carpetas.
O almenos asi lo creo yo :)
Publicar un comentario