




 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Robots.txt & sitemap.xml
Cuando se hace una auditoría de seguridad de una web es paso obligado consultar el fichero robots.txt para encontrar información jugosa que no se encuentra a través de los buscadores. Lo cierto es que este ficherito, se convierte en buen compañero del auditor revelando en muchos casos más información de la debida cuando, curiosamente, se había creado para lo contrario.
El fichero robots.txt se creó para indicar a los bots que se dedican a hacer crawling qué deben y qué no deben indexar para evitar que información importante quede almacenada en un buscador al alcance de cualquiera. Bueno, no sólo para esto, también para conseguir un mejor rendimiento del servidor ya que, antes del estallido de las técnicas SEO muchos estaban preocupados por la carga de trabajo que generaban en los servidores web la llegada de los bots.
Sin embargo, no deja de ser curiosa la información que de allí se saca por muchos motivos. Algunas veces por la cantidad de detalles que se ponen en los comandos Disallow, que llegan a poner el nombre del fichero completo como este de la página web del premio Alfred N.

Parte del robot.txt de la página de los premios Nobel
Otros, simplemente porque te ayudan a encontrar las zonas de administración internas y a reconocer el software. Este ejemplo es el del caso del ministerio de la vivienda, en el que se puede saber, no sólo la ruta de administración –por suerte hoy no publicada después del incidente-, sino también la versión de software que hay corriendo.
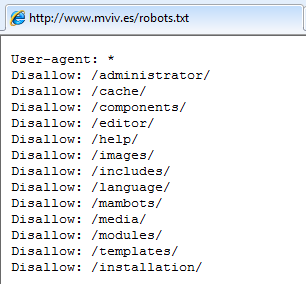
Robots.txt de la web del ministerio de la vivienda en España
Algunos son curiosos, como el de Google, que es enorme y me tuvo intrigadísimo que se quedaran pruebas ahí publicadas, como /u/ o /c/ y que incluso esta segunda desapareciera. ¿Os imagináis que Google se autoindexara recursivamente como lo de buscar Google en Google?
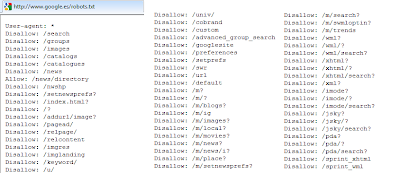
Parte del Robots.txt de Google.es
Una mala configuración del fichero robots.txt puede hacer:
a) Que el bot tarde más en indexar y se penalice el rendimiento del servidor.
b) Que documentos que se desean públicos no queden publicados
c) Que documentos que no se desean públicos queden publicados
d) Que se descubran rutas, zonas de administración o versiones de software utilizadas
Configurar un robots.txt no es muy complicado, y suele ser más un problema de despiste que de conocimiento en sí. Muchas herramientas ya lo configuran por defecto, lo que se puede utilizar para hacer un poco de fingerprinting sobre el sw que se está utilizando y algunos optan por el famoso disallow:* intentando que nada quede en los buscadores. Sin embargo, cuando te encuentras esto, se pasa directamente a la fase de buscar sus buscadores internos.
Quizá la mejor opción es configurar un robots.txt más o menos público, pero que oculte bien los directorios importantes sin dar mucha información en la ruta de los mismos.
Para los amantes del SEO se crearon los sitemap.xml que son más evolucionados y permiten optimizar la frecuencia de optimización y la carga del servidor. Si tienes un sitemap bien configurado en el que se definen, simplemente, las fechas de última modificación de los ficheros, el agente no indexará si ya lo tiene y mejorará el funcionamiento. De nuevo, un exceso de publicación en los sitemaps.xml puede ser muy favorecedor para el atacante.
Por último, me gustaría destacar el buenhacer del uso de las tecnologías en la web de EU2010 que, no sólo no se dignaron ni a pasar la copia gratuita de Acunetix, que detecta XSS for free, sino que han pasado en canoa de sitemaps.xml, robots.txt y cosas así, total, con su opencms ellos lo valen.
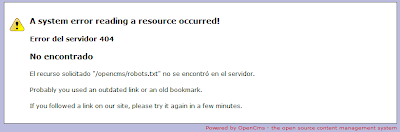
eu2010 sin robots.txt
Saludos Malignos!
El fichero robots.txt se creó para indicar a los bots que se dedican a hacer crawling qué deben y qué no deben indexar para evitar que información importante quede almacenada en un buscador al alcance de cualquiera. Bueno, no sólo para esto, también para conseguir un mejor rendimiento del servidor ya que, antes del estallido de las técnicas SEO muchos estaban preocupados por la carga de trabajo que generaban en los servidores web la llegada de los bots.
Sin embargo, no deja de ser curiosa la información que de allí se saca por muchos motivos. Algunas veces por la cantidad de detalles que se ponen en los comandos Disallow, que llegan a poner el nombre del fichero completo como este de la página web del premio Alfred N.

Parte del robot.txt de la página de los premios Nobel
Otros, simplemente porque te ayudan a encontrar las zonas de administración internas y a reconocer el software. Este ejemplo es el del caso del ministerio de la vivienda, en el que se puede saber, no sólo la ruta de administración –por suerte hoy no publicada después del incidente-, sino también la versión de software que hay corriendo.

Robots.txt de la web del ministerio de la vivienda en España
Algunos son curiosos, como el de Google, que es enorme y me tuvo intrigadísimo que se quedaran pruebas ahí publicadas, como /u/ o /c/ y que incluso esta segunda desapareciera. ¿Os imagináis que Google se autoindexara recursivamente como lo de buscar Google en Google?

Parte del Robots.txt de Google.es
Una mala configuración del fichero robots.txt puede hacer:
a) Que el bot tarde más en indexar y se penalice el rendimiento del servidor.
b) Que documentos que se desean públicos no queden publicados
c) Que documentos que no se desean públicos queden publicados
d) Que se descubran rutas, zonas de administración o versiones de software utilizadas
Configurar un robots.txt no es muy complicado, y suele ser más un problema de despiste que de conocimiento en sí. Muchas herramientas ya lo configuran por defecto, lo que se puede utilizar para hacer un poco de fingerprinting sobre el sw que se está utilizando y algunos optan por el famoso disallow:* intentando que nada quede en los buscadores. Sin embargo, cuando te encuentras esto, se pasa directamente a la fase de buscar sus buscadores internos.
Quizá la mejor opción es configurar un robots.txt más o menos público, pero que oculte bien los directorios importantes sin dar mucha información en la ruta de los mismos.
Para los amantes del SEO se crearon los sitemap.xml que son más evolucionados y permiten optimizar la frecuencia de optimización y la carga del servidor. Si tienes un sitemap bien configurado en el que se definen, simplemente, las fechas de última modificación de los ficheros, el agente no indexará si ya lo tiene y mejorará el funcionamiento. De nuevo, un exceso de publicación en los sitemaps.xml puede ser muy favorecedor para el atacante.
Por último, me gustaría destacar el buenhacer del uso de las tecnologías en la web de EU2010 que, no sólo no se dignaron ni a pasar la copia gratuita de Acunetix, que detecta XSS for free, sino que han pasado en canoa de sitemaps.xml, robots.txt y cosas así, total, con su opencms ellos lo valen.

eu2010 sin robots.txt
Saludos Malignos!

















7 comentarios:
¿Premios Novel?
¡Nobel es con B de burro!
quizas eran premios novell :P
@Anónimo, cuanto nerviosismo... ya lo cambié. Si es que escribir un post a las 12 de la noche de un domingo desde el water tiene lo que tiene...
Maligno pelsistil en su elol y no vel ni colegil.
Fdo. Talibán Oltogláfico
PS: Repetid conmigo, no imaginar a Chema escribiendo el post, no imaginar a Chema escribiendo el post ...
Nobel o novel... Buena entrada ;)
Newlog
Si es que Don Alfredo sólo hay uno....
Qué curioso, a eu2010.es le pides el /robots.txt de la raíz y te dice que no encuentra /opencms/robots.txt, como si tuviera configurada alguna redirección interna del tipo "si no lleva /opencms delante, añádeselo".
Publicar un comentario