





 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Time-Based Blind SQL Injection using Heavy Queries (Parte II de II)
***************************************************************************************
Artículo Publicado en la revista Hackin9 en Ene'08
- Time-Based Blind SQL Injection using Heavy Queries (I de II)
- Time-Based Blind SQL Injection using Heavy Queries (II de II)
***************************************************************************************
Time-Based Blind SQL Injection using heavy Queries
Sea como fuere, si en un ataque a ciegas se quiere saber si el valor ASCII de una determinada letra de un campo es mayor que un número estamos hablando de una condición no excesivamente pesada y se va a poder generar siempre una consulta más pesada que ella con facilidad. El objetivo del ataque es generar una consulta pesada que provoque un retardo de tiempos en la respuesta del motor de la base de datos que solo se ejecute sí y solo sí la condición que nos interesa vale TRUE. Esto implicaría que un retardo de tiempo es equivalente a un valor TRUE en la consulta ligera.
¿Cómo generar consultas pesadas?
La forma más sencilla de generar consultas pesadas es usar lo que más hace trabajar a las bases de datos, los productos cartesianos de tablas, es decir, unir una tabla con otra y con otra hasta generar una cantidad de registros tan grande que obliguen al servidor a consumir un tiempo medible en procesarlo. Para ello basta con conocer o averiguar o adivinar una tabla del sistema de bases de datos, que tenga algún registro, y unirla consigo misma hasta generar un tiempo medible. Vamos a ver algunos ejemplos.
Oracle
La siguente consulta, lanzada contra un servidor de pruebas, muestra en color azul la consulta pesada y en color roja la consulta de la que deseamos averiguar la respuesta. Lógicamente, en este caso, la respuesta ha de ser TRUE pues hemos utilizado el valor 300 que es mayor que cualquier valor ASCII:
http://blind.elladodelmal.com/oracle/pista.aspx?id_pista=1 and (select count(*) from all_users t1, all_users t2, all_users t3, all_users t4, all_users t5)>0 and 300>ascii(SUBSTR((select username from all_users where rownum = 1),1,1))
Lanzando esta consulta con la utilidad wget podemos ver una medición de tiempos:
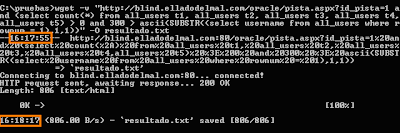 Imagen: La consulta dura 22 segundos, luego la respuesta es VERDADERO.
Imagen: La consulta dura 22 segundos, luego la respuesta es VERDADERO.
Si forzamos que la segunda condición, la ligera, valga FALSO, en este caso preguntando si 0 es mayor que el valor ASCII de la primera letra, podremos comprobar cómo la consulta pesada no se ejecuta y el tiempo de respuesta es menor.
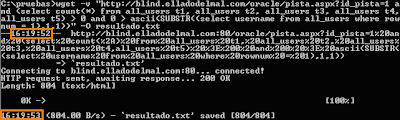 Imagen: La consulta dura 1 segundo, luego la respuesta es FALSO.
Imagen: La consulta dura 1 segundo, luego la respuesta es FALSO.
Como se puede ver en la consulta generada se ha utilizado 5 veces la vista all_users, pero esto no quiere decir que sea el número de tablas que deban utilizarse para todas las bases de datos Oracle, ya que el retardo de tiempo dependerá de la configuración del servidor y el número de registros que tenga la tabla. Lo que es absolutamente cierto es que se puede medir un retardo de tiempo y puede automatizarse este sistema.
Microsoft Access
Los motores Microsoft Access no tienen funciones de retardo de tiempo, pero las bases de datos Access tienen un pequeño diccionario de datos compuesto por una serie de tablas. En las versiones de Microsoft Access 97 y 2000 es posible acceder a la tabla MSysAccessObjects y las versiones 2003 y 2007 a la tabla MSysAccessStorage y generar, mediante uniones de estas tablas consultas pesadas que generen retardos de tiempos medibles. Por ejmplo, para una base de datos con Access 2003, podríamos ejecutar la siguiente consulta:
http://blind.access2007.foo/Blind3/pista.aspx?id_pista=1 and (SELECT count(*) from MSysAccessStorage t1, MSysAccessStorage t2, MSysAccessStorage t3, MSysAccessStorage t4, MSysAccessStorage t5, MSysAccessStorage t6) > 0 and exists (select * from contrasena)
En azul la consulta pesada y en rojo la consulta de la que queremos respuesta, es decir, si existe la tabla llamada “contrasena”. Como se puede ver en la captura realizada con la utilidad wget la consulta dura 39 segundos, luego, la consulta pesada, en este caso muy pesada para este entorno, se ha ejecutado por lo que el valor es VERDADERO, la tabla “contrasena” existe y tiene registros.
 Imagen: La consulta dura 39 segundos, luego la respuesta es VERDADERO.
Imagen: La consulta dura 39 segundos, luego la respuesta es VERDADERO.
Para comprobarlo realizados la negación de la consulta ligera y medimos el tiempo de respuesta:
 Imagen: La consulta dura menos de 1 segundo, luego la respuesta es FALSO.
Imagen: La consulta dura menos de 1 segundo, luego la respuesta es FALSO.
MySQL
En las versiones 5.x de los motores MySQL es posible conocer a priori un montón de tablas de acceso, de la misma forma que sucede en todos los sistemas que tienen diccionarios de datos. En el caso de MySQL se pueden generar consultas pesadas utilizando cualquiera de las tablas de Information_schema, como por ejemplo la tabla columns.
http://blind.mysql5.foo/pista.aspx?id_pista=1 and exists (select * from contrasena) and 300 > (select count(*) from information_schema.columns, information_schema.columns T1, information_schema T2)
En azul la consulta pesada y en rojo la consulta de la que se desea una respuesta VERDADERA o FASLA.
En las versiones 4.x y anteriores la elección de la tabla debe ser conocida o adivinada ya que no comparten un catálogo que por defecto sea accesible desde fuera.
Microsoft SQL Server
Con los motores de bases de datos Microsoft SQL Server se cuenta con un diccionario de datos por cada base de datos y además un diccionario global del servidor mantenido en la base de datos master. Para generar una consulta pesada se puede intentar utilizar cualquier tabla de esas, como por ejemplo las tablas sysusers, sysobjects o syscolumns. El ejemplo siguiente muestra una consulta pesada para un motor Microsoft SQL Server 2000. De nuevo en azul la consulta pesada y en rojo la que buscamos respuesta:
http://blind.sqlserver2k.foo/blind2/pista.aspx?id_pista=1 and (SELECT count(*) FROM sysusers AS sys1, sysusers as sys2, sysusers as sys3, sysusers AS sys4, sysusers AS sys5, sysusers AS sys6, sysusers AS sys7, sysusers AS sys8)>0 and 100>(select top 1 ascii(substring(name,1,1)) from sysusers)
Otros motores de bases de datos
El método funciona de igual forma en otros motores de bases de datos. Al final la idea es sencilla, hacer trabajar el motor de base de datos usando técnicas de anti optimización. Como la explotación depende del entorno es necesario un proceso de ajuste de la consulta pesada para cada entorno y además, al ser basado en tiempos, hay que tener en cuenta las características del medio de transmisión. Siempre es recomendable realizar varias pruebas para comprobar que los resultados son correctos.
Contramedidas
Evitar estas técnicas es lo mismo que evitar las vulnerabilidades de SQL Injection. Para evitar que una aplicación sea vulnerable a ellas se han escrito y es fácil encontrar guías de precauciones a seguir y como hacerlo en cada lenguaje de programación en concreto. Sin embargo no me gustaría terminar sin recomendar el uso de las herramientas de Análisis Estático de Código. Estas herramientas son una ayuda más al ojo del programador a la hora de evitar vulnerabilidades en el código.
Lógicamente no son perfectas y se necesita de un programador experimentado y preparado para el desarrollo seguro de aplicaciones, pero sí son un apoyo más. Herramientas como Fxcop ayudan a detectar las vulnerabilidades mediante el análisis del código. Existen múltiples herramientas de este tipo y especializadas en distintos lenguajes.
Artículo Publicado en la revista Hackin9 en Ene'08
- Time-Based Blind SQL Injection using Heavy Queries (I de II)
- Time-Based Blind SQL Injection using Heavy Queries (II de II)
***************************************************************************************
Time-Based Blind SQL Injection using heavy Queries
Sea como fuere, si en un ataque a ciegas se quiere saber si el valor ASCII de una determinada letra de un campo es mayor que un número estamos hablando de una condición no excesivamente pesada y se va a poder generar siempre una consulta más pesada que ella con facilidad. El objetivo del ataque es generar una consulta pesada que provoque un retardo de tiempos en la respuesta del motor de la base de datos que solo se ejecute sí y solo sí la condición que nos interesa vale TRUE. Esto implicaría que un retardo de tiempo es equivalente a un valor TRUE en la consulta ligera.
¿Cómo generar consultas pesadas?
La forma más sencilla de generar consultas pesadas es usar lo que más hace trabajar a las bases de datos, los productos cartesianos de tablas, es decir, unir una tabla con otra y con otra hasta generar una cantidad de registros tan grande que obliguen al servidor a consumir un tiempo medible en procesarlo. Para ello basta con conocer o averiguar o adivinar una tabla del sistema de bases de datos, que tenga algún registro, y unirla consigo misma hasta generar un tiempo medible. Vamos a ver algunos ejemplos.
Oracle
La siguente consulta, lanzada contra un servidor de pruebas, muestra en color azul la consulta pesada y en color roja la consulta de la que deseamos averiguar la respuesta. Lógicamente, en este caso, la respuesta ha de ser TRUE pues hemos utilizado el valor 300 que es mayor que cualquier valor ASCII:
http://blind.elladodelmal.com/oracle/pista.aspx?id_pista=1 and (select count(*) from all_users t1, all_users t2, all_users t3, all_users t4, all_users t5)>0 and 300>ascii(SUBSTR((select username from all_users where rownum = 1),1,1))
Lanzando esta consulta con la utilidad wget podemos ver una medición de tiempos:
 Imagen: La consulta dura 22 segundos, luego la respuesta es VERDADERO.
Imagen: La consulta dura 22 segundos, luego la respuesta es VERDADERO.Si forzamos que la segunda condición, la ligera, valga FALSO, en este caso preguntando si 0 es mayor que el valor ASCII de la primera letra, podremos comprobar cómo la consulta pesada no se ejecuta y el tiempo de respuesta es menor.
 Imagen: La consulta dura 1 segundo, luego la respuesta es FALSO.
Imagen: La consulta dura 1 segundo, luego la respuesta es FALSO.Como se puede ver en la consulta generada se ha utilizado 5 veces la vista all_users, pero esto no quiere decir que sea el número de tablas que deban utilizarse para todas las bases de datos Oracle, ya que el retardo de tiempo dependerá de la configuración del servidor y el número de registros que tenga la tabla. Lo que es absolutamente cierto es que se puede medir un retardo de tiempo y puede automatizarse este sistema.
Microsoft Access
Los motores Microsoft Access no tienen funciones de retardo de tiempo, pero las bases de datos Access tienen un pequeño diccionario de datos compuesto por una serie de tablas. En las versiones de Microsoft Access 97 y 2000 es posible acceder a la tabla MSysAccessObjects y las versiones 2003 y 2007 a la tabla MSysAccessStorage y generar, mediante uniones de estas tablas consultas pesadas que generen retardos de tiempos medibles. Por ejmplo, para una base de datos con Access 2003, podríamos ejecutar la siguiente consulta:
http://blind.access2007.foo/Blind3/pista.aspx?id_pista=1 and (SELECT count(*) from MSysAccessStorage t1, MSysAccessStorage t2, MSysAccessStorage t3, MSysAccessStorage t4, MSysAccessStorage t5, MSysAccessStorage t6) > 0 and exists (select * from contrasena)
En azul la consulta pesada y en rojo la consulta de la que queremos respuesta, es decir, si existe la tabla llamada “contrasena”. Como se puede ver en la captura realizada con la utilidad wget la consulta dura 39 segundos, luego, la consulta pesada, en este caso muy pesada para este entorno, se ha ejecutado por lo que el valor es VERDADERO, la tabla “contrasena” existe y tiene registros.
 Imagen: La consulta dura 39 segundos, luego la respuesta es VERDADERO.
Imagen: La consulta dura 39 segundos, luego la respuesta es VERDADERO.Para comprobarlo realizados la negación de la consulta ligera y medimos el tiempo de respuesta:
 Imagen: La consulta dura menos de 1 segundo, luego la respuesta es FALSO.
Imagen: La consulta dura menos de 1 segundo, luego la respuesta es FALSO.MySQL
En las versiones 5.x de los motores MySQL es posible conocer a priori un montón de tablas de acceso, de la misma forma que sucede en todos los sistemas que tienen diccionarios de datos. En el caso de MySQL se pueden generar consultas pesadas utilizando cualquiera de las tablas de Information_schema, como por ejemplo la tabla columns.
http://blind.mysql5.foo/pista.aspx?id_pista=1 and exists (select * from contrasena) and 300 > (select count(*) from information_schema.columns, information_schema.columns T1, information_schema T2)
En azul la consulta pesada y en rojo la consulta de la que se desea una respuesta VERDADERA o FASLA.
En las versiones 4.x y anteriores la elección de la tabla debe ser conocida o adivinada ya que no comparten un catálogo que por defecto sea accesible desde fuera.
Microsoft SQL Server
Con los motores de bases de datos Microsoft SQL Server se cuenta con un diccionario de datos por cada base de datos y además un diccionario global del servidor mantenido en la base de datos master. Para generar una consulta pesada se puede intentar utilizar cualquier tabla de esas, como por ejemplo las tablas sysusers, sysobjects o syscolumns. El ejemplo siguiente muestra una consulta pesada para un motor Microsoft SQL Server 2000. De nuevo en azul la consulta pesada y en rojo la que buscamos respuesta:
http://blind.sqlserver2k.foo/blind2/pista.aspx?id_pista=1 and (SELECT count(*) FROM sysusers AS sys1, sysusers as sys2, sysusers as sys3, sysusers AS sys4, sysusers AS sys5, sysusers AS sys6, sysusers AS sys7, sysusers AS sys8)>0 and 100>(select top 1 ascii(substring(name,1,1)) from sysusers)
Otros motores de bases de datos
El método funciona de igual forma en otros motores de bases de datos. Al final la idea es sencilla, hacer trabajar el motor de base de datos usando técnicas de anti optimización. Como la explotación depende del entorno es necesario un proceso de ajuste de la consulta pesada para cada entorno y además, al ser basado en tiempos, hay que tener en cuenta las características del medio de transmisión. Siempre es recomendable realizar varias pruebas para comprobar que los resultados son correctos.
Contramedidas
Evitar estas técnicas es lo mismo que evitar las vulnerabilidades de SQL Injection. Para evitar que una aplicación sea vulnerable a ellas se han escrito y es fácil encontrar guías de precauciones a seguir y como hacerlo en cada lenguaje de programación en concreto. Sin embargo no me gustaría terminar sin recomendar el uso de las herramientas de Análisis Estático de Código. Estas herramientas son una ayuda más al ojo del programador a la hora de evitar vulnerabilidades en el código.
Lógicamente no son perfectas y se necesita de un programador experimentado y preparado para el desarrollo seguro de aplicaciones, pero sí son un apoyo más. Herramientas como Fxcop ayudan a detectar las vulnerabilidades mediante el análisis del código. Existen múltiples herramientas de este tipo y especializadas en distintos lenguajes.
Referencias
- OWASP Top 10. The Ten Most Critical Web Applications Security Vulnerabilities
- NT Web Technology Vulnerabilities
- Advanced SQL Injection
- (more) Advanced SQL Injection
- Blind SQL Injection Automation Techniques
- Blind XPath Injection
- Protección contra Blind SQL Injection
- Time-Based Blind SQL Injection using Heavy Queries
Herramientas
- SQLBftools
- SQLNinja
- Absinthee
- SQL PowerInjector
***************************************************************************************
Artículo Publicado en la revista Hackin9 en Ene'08
- Time-Based Blind SQL Injection using Heavy Queries (I de II)
- Time-Based Blind SQL Injection using Heavy Queries (II de II)
***************************************************************************************
















3 comentarios:
Para mysql también puedes generar consultas pesadas con benchmark:
select if (codigo=concat(char(83),char(65),char(83)),38,benchmark(100000000,char(77))) from usuarios
Pudiendo ajustar la cantidad de repeticiones para tardar más o menos tiempo.
:P buen blog si señó
Buenos dias!,
Deacuerdo con lo que entendi aqui el otro dia sobre la optimizacion de querys sql, no procesaba en primer lugar la primera condicion y luego la segunda?, osea, de izquierda a derecha? o influye tambien el numero de registros de cada la operacion cartesiana?, porque sino no entiendo porque primero va la consulta pesada y luego la ligera, tal y como lo estoy entendiendo la pesada se ejecutaria siempre, y si luego la ligera:
true & (true|false),
En la practica parece ser que se hace alreves? Porque?
@TheSur, depende del motor de la base de datos. Los que utilizan predicción generan un plan de ejecución independiente dónde coloques la clausula en el where.
Saludos!
Publicar un comentario