




 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Técnicas SEO para gente de moral relajada [I de VI]
**********************************************************************************************
- Técnicas SEO para gente de moral relajada [I de VI]
- Técnicas SEO para gente de moral relajada [II de VI]
- Técnicas SEO para gente de moral relajada [III de VI]
- Técnicas SEO para gente de moral relajada [IV de VI]
- Técnicas SEO para gente de moral relajada [V de VI]
- Técnicas SEO para gente de moral relajada [VI de VI]
Autores: Chema Alonso & Enrique Rando
**********************************************************************************************
Justificación
Hay algo en lo que los distintos estudios sobre el uso de buscadores de Internet coinciden: casi todos los usuarios hacen clic en algunos de los enlaces de la primera página de resultados. Muchos lo hacen en los de la segunda. Hay quien, incluso, visita algunas de las direcciones listadas en la tercera, pero casi nadie pasa de ahí. Aparecer en la quinta página de resultados es casi lo mismo que no aparecer. Y, para una empresa u organización, eso puede significar no tener relevancia en el sector, no hacer negocio, carecer de publicidad… En definitiva, no existir.
No es de extrañar que existan empresas que se dedican al posicionamiento en buscadores, es decir, a conseguir subir la relevancia de una página dada dentro de los resultados asociados a una determinada búsqueda. Pero no todas ellas realizan su trabajo de forma honesta: existe una nueva clase de empresarios de “moral relajada” que utilizan sus propias técnicas, no siempre legales, para obtener sus beneficios.
El presente artículo no es un artículo sobre SEO, sino de algunas técnicas y trucos, menos legales que más, que algunos usan para conseguir aparecer en las primeras posiciones de los resultados a una determinada búsqueda sin pagar el coste de los enlaces patrocinados.
Breve resumen de la historia del SEO para dummies
Inicialmente, la relevancia de una página respecto a una cadena de búsqueda, se debía, única y exclusivamente, al contenido de la página. Para ello, los procesos de indexación y análisis de contenidos de una página realizaban un thesaurus de la misma. Es decir, leían todas las palabras, se quitaban todas las palabras ruido como artículos, preposiciones, conjunciones, etc…, después de contaban las repeticiones de la misma palabra, se medía su importancia respecto del tamaño total de la página, se miraban sinónimos de la misma palabra e incluso se buscaban las palabras especiales, es decir, las que eran menos comunes para darles mayor importancia. Otro de los aspectos que se evalúa dentro de una página web es, lógicamente, la ubicación del término dentro de la misma. No es igual que la palabra esté en el título que en una etiqueta meta, dentro del comentario de un visitante, en el texto de un botón o en que forme parte de un párrafo de texto. La ubicación cuenta.
Spamdexing
Pero hacia la segunda mitad de los 90 este esquema dejó de ser válido. Hasta ese momento muchas webs eran diseñadas específicamente para atraer la atención de los buscadores, normalmente incluyendo numerosos tags META, con palabras en muchos casos no tenían relación con los contenidos de las páginas. A esta práctica se le conoció como “spamdexing”.
La respuesta de los buscadores fue basar el orden de sus resultados en criterios más objetivos que los contenidos de la página. Y en el nuevo modelo los enlaces jugaron un papel fundamental.
Así, el número de enlaces entrantes y salientes definen la importancia de una página, su “peso” en Internet. Supongamos que una página tiene 20 links que apuntan a ella y ella apunta a 3. Cada uno de las 20 páginas que le apuntan tendrá su propia relevancia y, en función de ésta, le aportarán parte de su importancia en cada enlace. Del mismo modo, cada uno de los tres enlaces presentes en esta página proporcionará relevancia a las páginas destino.
Dicha relevancia se utiliza para modificar el valor de una palabra en una búsqueda. Así, cuando se hace una búsqueda de un término, se mira, tanto el contenido de la web, como el contenido de los links que apuntan a esa página y la relevancia de las páginas web de las que proceden los links.
La relevancia se mide por página y no por dominio como muchos hemos creido alguna vez, así que la importancia de la ubicación de un link dentro de un dominio también importa. No es lo mismo la página principal de un sitio que puede tener un valor alto, como un link puesto en una página interior que tenga una valor bajo. Los valores de una página se pueden consultar en muchos lugares. Hay un buscador en SEOchat.
Bombas Google
Conociendo este comportamiento era posible conseguir que en los primeros resultados de un término apareciera una página en la que no se encuentra, por ningún sitio, el término buscado. Un ejemplo clásico de esto es el de la palabra “ladrones” que fue usado masivamente para enlazar la web de la SGAE.
A conseguir este objetivo, es decir, asociar una palabra que no tenía nada que ver con el destino de forma "fraudulenta" se conoce como Google Bombing. Esto se utilizó con muchos políticos en España para asociarles términos como indeseable, asesino, etc...
Google decidió cambiar la forma en que funcionaba el algoritmo de relevancia para detectar estas bombas en el año 2007 aunque la importancia de los términos siguió siendo importante, y, por supuesto la relevancia de la web se sigue midiendo en enlaces de entrada. Para detectar bombas lo que intenta el algoritmo de Google es averiguar cuando el término y la página destino realmente no tienen nada que ver. Pero hecha la ley hecha la trampa. ¿Qué tal apuntar a un link de la SGAE con la palabra ladrones a pesar de que éste no sea un valor correcto?
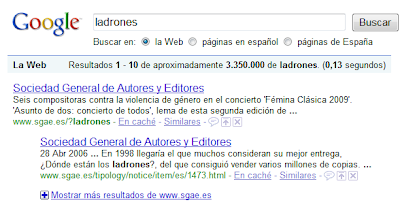
Figura 1: De 3.350.000 páginas con información sobre el término ladrones, la SGAE es la primera.
Algunas grandes empresas han utilizado sistemas tramposos similares para conseguir subir la relevancia de campañas de promoción. Un ejemplo de esto el caso de BMW Alemania. Esta web comprobaba el valor del campo user-agent del cliente que realizaba la petición y, si era el robot de Google, le entregaba una página totalmente distinta a la que podía ver un usuario. Esto le permitía a la página ofrecer una página mucho más enfocada a la indexación y que realmente correspondía con todos los links que había comprado, pero sin embargo, la página de verdad que vería un usuario no era tan relevante como la que veía el indexador. Google detectó este comportamiento y eliminó esta página de la base de datos del buscador hasta que no cambiara su comportamiento.

Figura 2: Página que veía el agente de google
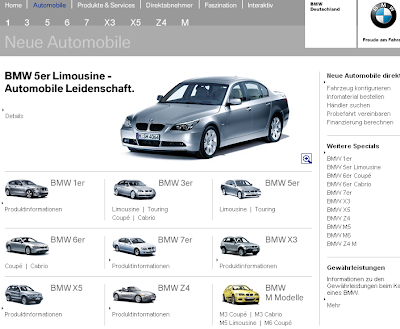
Figura 3: Página que veían los navegantes
Este truco de utilizar páginas distintas para el navegador y para el usuario había sido muy utilizado por los pobres diseñadores Flash, que tanto les costaba que el contenido de sus swf generara relevancia en las búsquedas.
**********************************************************************************************
- Técnicas SEO para gente de moral relajada [I de VI]
- Técnicas SEO para gente de moral relajada [II de VI]
- Técnicas SEO para gente de moral relajada [III de VI]
- Técnicas SEO para gente de moral relajada [IV de VI]
- Técnicas SEO para gente de moral relajada [V de VI]
- Técnicas SEO para gente de moral relajada [VI de VI]
Autores: Chema Alonso & Enrique Rando
**********************************************************************************************
- Técnicas SEO para gente de moral relajada [I de VI]
- Técnicas SEO para gente de moral relajada [II de VI]
- Técnicas SEO para gente de moral relajada [III de VI]
- Técnicas SEO para gente de moral relajada [IV de VI]
- Técnicas SEO para gente de moral relajada [V de VI]
- Técnicas SEO para gente de moral relajada [VI de VI]
Autores: Chema Alonso & Enrique Rando
**********************************************************************************************
Justificación
Hay algo en lo que los distintos estudios sobre el uso de buscadores de Internet coinciden: casi todos los usuarios hacen clic en algunos de los enlaces de la primera página de resultados. Muchos lo hacen en los de la segunda. Hay quien, incluso, visita algunas de las direcciones listadas en la tercera, pero casi nadie pasa de ahí. Aparecer en la quinta página de resultados es casi lo mismo que no aparecer. Y, para una empresa u organización, eso puede significar no tener relevancia en el sector, no hacer negocio, carecer de publicidad… En definitiva, no existir.
No es de extrañar que existan empresas que se dedican al posicionamiento en buscadores, es decir, a conseguir subir la relevancia de una página dada dentro de los resultados asociados a una determinada búsqueda. Pero no todas ellas realizan su trabajo de forma honesta: existe una nueva clase de empresarios de “moral relajada” que utilizan sus propias técnicas, no siempre legales, para obtener sus beneficios.
El presente artículo no es un artículo sobre SEO, sino de algunas técnicas y trucos, menos legales que más, que algunos usan para conseguir aparecer en las primeras posiciones de los resultados a una determinada búsqueda sin pagar el coste de los enlaces patrocinados.
Breve resumen de la historia del SEO para dummies
Inicialmente, la relevancia de una página respecto a una cadena de búsqueda, se debía, única y exclusivamente, al contenido de la página. Para ello, los procesos de indexación y análisis de contenidos de una página realizaban un thesaurus de la misma. Es decir, leían todas las palabras, se quitaban todas las palabras ruido como artículos, preposiciones, conjunciones, etc…, después de contaban las repeticiones de la misma palabra, se medía su importancia respecto del tamaño total de la página, se miraban sinónimos de la misma palabra e incluso se buscaban las palabras especiales, es decir, las que eran menos comunes para darles mayor importancia. Otro de los aspectos que se evalúa dentro de una página web es, lógicamente, la ubicación del término dentro de la misma. No es igual que la palabra esté en el título que en una etiqueta meta, dentro del comentario de un visitante, en el texto de un botón o en que forme parte de un párrafo de texto. La ubicación cuenta.
Spamdexing
Pero hacia la segunda mitad de los 90 este esquema dejó de ser válido. Hasta ese momento muchas webs eran diseñadas específicamente para atraer la atención de los buscadores, normalmente incluyendo numerosos tags META, con palabras en muchos casos no tenían relación con los contenidos de las páginas. A esta práctica se le conoció como “spamdexing”.
La respuesta de los buscadores fue basar el orden de sus resultados en criterios más objetivos que los contenidos de la página. Y en el nuevo modelo los enlaces jugaron un papel fundamental.
Así, el número de enlaces entrantes y salientes definen la importancia de una página, su “peso” en Internet. Supongamos que una página tiene 20 links que apuntan a ella y ella apunta a 3. Cada uno de las 20 páginas que le apuntan tendrá su propia relevancia y, en función de ésta, le aportarán parte de su importancia en cada enlace. Del mismo modo, cada uno de los tres enlaces presentes en esta página proporcionará relevancia a las páginas destino.
Dicha relevancia se utiliza para modificar el valor de una palabra en una búsqueda. Así, cuando se hace una búsqueda de un término, se mira, tanto el contenido de la web, como el contenido de los links que apuntan a esa página y la relevancia de las páginas web de las que proceden los links.
La relevancia se mide por página y no por dominio como muchos hemos creido alguna vez, así que la importancia de la ubicación de un link dentro de un dominio también importa. No es lo mismo la página principal de un sitio que puede tener un valor alto, como un link puesto en una página interior que tenga una valor bajo. Los valores de una página se pueden consultar en muchos lugares. Hay un buscador en SEOchat.
Bombas Google
Conociendo este comportamiento era posible conseguir que en los primeros resultados de un término apareciera una página en la que no se encuentra, por ningún sitio, el término buscado. Un ejemplo clásico de esto es el de la palabra “ladrones” que fue usado masivamente para enlazar la web de la SGAE.
A conseguir este objetivo, es decir, asociar una palabra que no tenía nada que ver con el destino de forma "fraudulenta" se conoce como Google Bombing. Esto se utilizó con muchos políticos en España para asociarles términos como indeseable, asesino, etc...
Google decidió cambiar la forma en que funcionaba el algoritmo de relevancia para detectar estas bombas en el año 2007 aunque la importancia de los términos siguió siendo importante, y, por supuesto la relevancia de la web se sigue midiendo en enlaces de entrada. Para detectar bombas lo que intenta el algoritmo de Google es averiguar cuando el término y la página destino realmente no tienen nada que ver. Pero hecha la ley hecha la trampa. ¿Qué tal apuntar a un link de la SGAE con la palabra ladrones a pesar de que éste no sea un valor correcto?

Figura 1: De 3.350.000 páginas con información sobre el término ladrones, la SGAE es la primera.
Algunas grandes empresas han utilizado sistemas tramposos similares para conseguir subir la relevancia de campañas de promoción. Un ejemplo de esto el caso de BMW Alemania. Esta web comprobaba el valor del campo user-agent del cliente que realizaba la petición y, si era el robot de Google, le entregaba una página totalmente distinta a la que podía ver un usuario. Esto le permitía a la página ofrecer una página mucho más enfocada a la indexación y que realmente correspondía con todos los links que había comprado, pero sin embargo, la página de verdad que vería un usuario no era tan relevante como la que veía el indexador. Google detectó este comportamiento y eliminó esta página de la base de datos del buscador hasta que no cambiara su comportamiento.

Figura 2: Página que veía el agente de google

Figura 3: Página que veían los navegantes
Este truco de utilizar páginas distintas para el navegador y para el usuario había sido muy utilizado por los pobres diseñadores Flash, que tanto les costaba que el contenido de sus swf generara relevancia en las búsquedas.
**********************************************************************************************
- Técnicas SEO para gente de moral relajada [I de VI]
- Técnicas SEO para gente de moral relajada [II de VI]
- Técnicas SEO para gente de moral relajada [III de VI]
- Técnicas SEO para gente de moral relajada [IV de VI]
- Técnicas SEO para gente de moral relajada [V de VI]
- Técnicas SEO para gente de moral relajada [VI de VI]
Autores: Chema Alonso & Enrique Rando
**********************************************************************************************

















23 comentarios:
Me ha gustado mucho este post, espero impaciente el resto de la serie.
Gracias!
Con las ganas que tengo de aprender SEO y nunca me ponía... Esto me va a ir de perlas!
Newlog
Muy interesante, ya se ha oido hablar de las trampas para la indexación. Yo he usado entradas en facebook, twiter y similares para promocionar mis webs, y la verdad es que me ha funcionado muy bien.
Ejem... no hace falta que comente, para que sepas de lo que te iba a hablar, ¿no?
que bueno!! más más!!
Si googleas Maligno, adivina que sitio sale...
Aunque eso tu ya lo sabes, pájaro ;-)
Muy interesante el post. Gracias por publicarlo para los que no pudimos ir de comuna friki.
Un saludo.
Manolo.
Por ahora lo que vas contando es un 98% cierto. Vamos bien. No vemos en Boecillo. Sigue!
Os veo muy atentos... pájaros!
No soy ningún extremista de la lengua y desde luego sé que en este mundillo tenemos muchos barabarismos aceptados, y no voy a dar lecciones porque yo soy malisimo en esto
Pero no me jodas, "macheaba" suena fatal. En alguna conferencia he escuchado lindeces como "frame time" (para la venta de un ataque), cash, full time y similares de compañeros tuyos de charla también.
Que conste que esto no es una ostia, sólo un poco de por favor.
Saludos figura.
@anónimo, llevas razón, voy a cambiar el término, pero tú pon hostia con hache, salvo que te refieras a ostras...
Saludos!
..jajajaj.. buena replica, maligno!! como diría alguien: pom, en toda la cara!!
Genial tu post, maldita sea!!
Y ahora tendré que estar pendiente de la continuación!!
Esperando, esperando, esperando los demás.
Muy bueno.
Muy interesante.
comprobaba el valor del campo user-agent del cliente que realizaba la petición
Esa técnica se llama en argot Cloaking y cabe comentar que es una táctica que utilizan algunos spammers/phishers cuando han conseguido hackear un servidor web, pero usando la cabecera referer en lugar del user-agent.
El truco es como sigue: a los usuarios que vienen de los indexadores (referer en [google.com, yahoo.com, bing.com, etc.]) los redirigen a una web de spam, mientra que a los que teclean el URL (referer == vacío) les muestran la web original.
El truco intenta llevar la mayor parte del tráfico de una web hacia páginas de spam (o phishing, defacement, lo que sea) mientras ésto se le oculta al dueño de la página. Suele funcionar por dos motivos:
1. Porque la mayor parte de propietarios de una web escriben directamente su URL, no lo buscan en un motor de búsqueda. Por lo tanto, no ven la web "falsa" que verán los que usan los motores de búsqueda (la mayor parte de sus usuarios)
2. Porque, incluso si descubren que algo falla cuando se accede a través de un motor de búsqueda, muchos administradores web creen que el fallo está en el motor de búsqueda en sí, y muy pocos caen en que la realidad es que han sido pwnd
Has salido en Microsiervos :D
Muy buena información
Que bien explicado! Algunos conceptos que aparecen los desconocia por completo. Seguire impaciente el resto de la serie!
Bueno bueno , realmante muy interesante tu post
Saludos
Rcg
caray muchas gracias, reconozco que soy malo y tratare de hacer uso de estas tecnicas
These SEO organizations have a technique obliging customers to pay the significant internet searchers (counting Google and
Yahoo) for month to month site support. Nonetheless, the organization has ensured SEO administrations
Whenever choosing a friendship to palm your firms SEO needs,head trusty they human the abilities needful SEO Courses Online seriously to make both off-page and on-page SEO that garners results. It's imperative that you gain a firm who specializes in every areas of seo and is most the track of regional Hunting Engine Optimization techniques. they are feat the activity,SEO Courses Online If your competitors are occupying the uttermost effectual position searching. Major net marketing experts gift improve elevate one to the top of search in a name of research-driven keywords. Junction a results convergent unfaltering using a create of success to inform much.
http://www.seoproducts.net/
Me parece que las técnicas SEO para gente moral, son esenciales actualmente.
Gracias por la información.
Bueno aunque me parece muy bueno tus comentarios enserio primero esta la moral seo pero me gusta mucho como escribes y como no mas sobreposicionamiento y optimizacion para las paginas web
Publicar un comentario