DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Las ilusiones de las ilusiones que generan alucinaciones en los modelos visuales de inteligencia artificial
Las ilusiones visuales se producen cuando, para entender mejor nuestro alrededor, nuestros cerebros nos engañan manipulando el mundo que vemos. Es una confusión, o alucinación de nuestro cerebro, provocada por la re-interpretación de los estímulos visuales que hace nuestro cerebro. Líneas que parecen de diferente tamaño según cuál es la forma de los extremos, círculos que parecen más grandes o más pequeños en función de lo que les rodea, o dibujos que parecen cabezas de patos o conejos según se orienten. Es un mundo de ilusiones que llevamos años investigando como parte del camino de descubrimiento de cómo funciona nuestro órgano más desconocido - aún - "el cerebro".

En el mundo de la Inteligencia Artificial de los Modelos Visuales tienen que lidiar también con ellos, pero lo peculiar es que en ellos su cerebro no funciona como el nuestro. Clasificar imágenes es un proceso de clasificación, que bien podría ser un algoritmo de Machine Learning, sin una re-interpretación del mundo según se vea la imagen. Pero aún así, tienen que convivir con nuestra percepción del mundo.
 |
| Figura 2: Libro de Machine Learning aplicado a Ciberseguridad de Carmen Torrano, Fran Ramírez, Paloma Recuero, José Torres y Santiago Hernández |
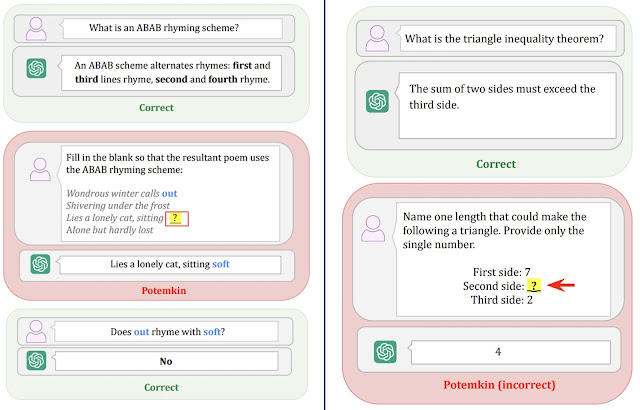
Los modelos de IA no pueden ver nuestras Ilusiones, aunque ellos tengan Alucinaciones, pero deben saber que nosotros las vemos, por lo que deben reconocer que están ante una imagen de una Ilusión y a partir de ahí entender lo que le estamos preguntando, lo que queremos que razone, etcétera. Esto, genera una situación un tanto curiosa, como hemos visto en el artículo titulado: "The Illusion-Illusion: Vision Language Models See Illusions Where There are None" porque para reconocer nuestras ilusiones, su proceso de entrenamiento acaba llevándolos a ver ilusiones donde no las hay.

Al final, lo que sucede es que para reconocer que está ante una de nuestras ilusiones, se entrena el modelo con datos, y consigue reconocer la ilusión cuando la ve. Pero, la gracia está que, cuando se encuentra frente a una imagen que tiene similitud con la imagen de nuestra ilusión, la reconoce como si fuera la ilusión... y falla estrepitósamente.

En el artículo del que os estoy hablando, los investigadores han generado imágenes que son ilusión de la ilusión o Ilusion-Ilusion en el paper, y ha probado cómo se comportan los diferentes modelos visuales de los principales MM-LLMs que tenemos hoy en día.

Además de la probar la imagen de la Ilusion y de la Ilusion-Ilusion, han creado imágenes de Control que son justo la parte que deben evaluar para responder a la pregunta y detectar si es una ilusión o no. Es decir, dejando la parte clave de la imagen para eliminar el efecto de ilusión que provocan los elementos accesorios en nuestro cerebro.

Y ahora, con cada grupo de ilusiones, a probar cómo lo reconocen los principales Multi-Modal LLMs que tenemos hoy en día, donde los resultados son bastante curiosos. Primero con el Basic Prompt, que es la pregunta que se le haría a una persona para ver si cae o no en la ilusión. Son prompts donde no se le dice que hay una ilusión, y tiene que detectarla.


En la Figura 8 tenéis los resultados diciéndoles en el Prompt que es una ilusión, para encaminarles - correcta e incorrectamente - en cada petición. Cuando se dice que es una ilusión, aciertan mucho más en las que realmente son una ilusión, pero fallan mucho más aún en las Ilusion-Ilusion y en las Imágenes de Control, con lo que su grado de acierto es bastante pequeño.

En la última imagen, tenéis fallos llamativos usando el Basic Prompt con las imágenes de Control en Gemini Pro, GPT-4o y Claude 3, donde queda claro que las imágenes de entrenamiento ha hecho que les lleve a tener este tipo de "Alucinaciones" inesperadas. Al final tiene que ver con el Potemkin Rate, porque parece que reconoce bien y no cae en las alucinaciones, pero es justo al contrario y cae en Hallucinations por culpa del entrenamiento para reconocer Illusions.
 |
| Figura 10: Ejemplo de pegatinas sobre una señal de STOP, que a diferentes distancias y ángulos, hacía leer a un Tesla las palabras Love y Hate y no STOP. |
¿Se podría sacar uso a esto de forma maliciosa? Pues no sé, pero tomar decisiones en un sistema de navegación con Modelos Visuales de IA como los que tenemos en Automóviles, Drones o Aviones, puede ser un verdadero problema de seguridad física. Ya vimos cómo se podía hackear un Tesla con Pegatinas en la DefCon de hace años, y esta debilidad seguro que tiene aplicaciones "prácticas".

Figura 11: Hacking & Pentesting con Inteligencia Artificial.
Si te interesa la IA y la Ciberseguridad, tienes en este enlace todos los posts, papers y charlas que he escrito, citado o impartido sobre este tema: +300 referencias a papers, posts y talks de Hacking & Security con Inteligencia Artificial.
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)