En el año 1998 el mundo de la informática conoció el troyano
NetBus. Esta pequeña aplicación fue lanzada como una herramienta de administración remota de máquinas, aunque existían algunas versiones más oscuras que eran utilizadas por atacantes para troyanizar máquinas. Yo dediqué tiempo a jugar con
NetBus cuando iba al instituto, allá por el año
2001, pero eso es otra historia.
En verano me dio por trastear y sacar del baúl de los recuerdos a software que hoy en día tienen poca aplicación, ya que son desbordados por otras herramientas con mucho más poder, pero apareció de nuevo el
NetBus.
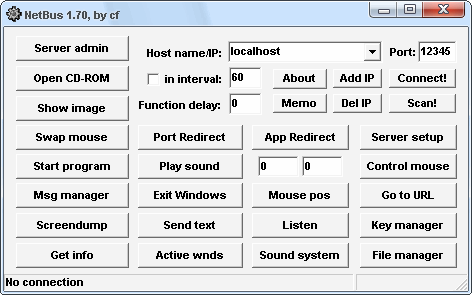 |
| Figura 1: NetBus 1.70 |
Decidí echarle un ojo, y ver cómo los creadores de
malware de la época hacían para transmitir la información y las órdenes desde un cliente a un servidor. Hay que recordar que el
malware de aquella época seguía una arquitectura cliente-servidor clásica. Cuando mandaban el fichero
patch.exe (servidor de
NetBus) a una víctima ésta disponía de una dirección
IP, la cual era una dirección pública. Esto hacía que cualquier usuario pudiera tener conectividad directa con dicha máquina. Después aparecieron los
routers y la idea tuvo que cambiarse y ser el “
bicho.exe” el que haga la conexión reversa a la máquina del atacante.
Fase 1: Detectando un NetBus
Echando un ojo con un
Wireshark a la interacción entre el cliente y servidor en una red me llamó la atención la facilidad con la que
NetBus se identificaba.
 |
| Figura 2: Tráfico de conexión a un servidor NetBus |
En la imagen se ve como el cliente, en este caso una versión 1.60, realiza la conexión con el servidor (
three-way handshake) y el servidor “escupe” un segmento con datos. Parece que el servidor muestra el
banner, como si de otro servicio normal se tratase. Con
Wireshark podemos ver que nos dice la versión a la que nos hemos conectado.
 |
| Figura 3: Versión de NetBus en el paquete de datos de conexión |
Al ver esto, y viendo que el verano por el norte no ha sido muy productivo a lo que horas de sol se refiere, me puse a trastear con
Ruby. Muchos saben que desde el libro de
Metasploit para pentesters un servidor anda con ganas de ir haciendo más y más cosas para el
framework, aunque no todo lo que me gustaría debido al poco tiempo libre. Para pasar el rato decidí codificar un
script en
Ruby para, dándole una dirección
IP, detectar un
NetBus y su versión.
 |
| Figura 4: Código en Ruby para detectar versión de NetBus |
En el código, muy sencillo, se puede ver como se abre un
socket contra una
Dirección IP y un
Puerto que, en la versión
1.60 de
NetBus es el
6000, es por el que se gestiona. Tras abrir el
socket esperamos a recibir un
“\r” que es el delimitador que utiliza
NetBus, algo que también se puede obtener del mensaje mostrado con
Wireshark anteriormente. En él se puede ver que cada comando o información enviada acaba con un
“\r”, en hexadecimal
0d.
Fase 2: Implementando el comando GetInfo de NetBus
Si lo que recibimos por el
socket encaja con la expresión regular definida para localizar un
banner de
NetBus se imprime por pantalla la versión. Como se puede imaginar esto es algo bastante rápido de montar, y el sol seguía sin salir por el norte así que decidí ir un poco más allá.
El cliente de
NetBus tiene diversos botones que permitían al atacante hacer maldades sobre sus víctimas. Pero, como ya hemos visto antes, la comunicación era trivial, el texto plano es la clave. Al probar el botón de
Get Info, el cliente obtiene algo de información de la máquina remota, por ejemplo el
Usuario con el que se está conectado en el sistema operativo, la ruta dónde se encuentra el
patch.exe o el número de clientes conectados. Si observamos la trama en
Wireshark veremos que el comando no puede ser más sencillo
“Get Info”, escrito a través del
socket, eso sí, que no se nos olvidé el
0d al final, o lo que es lo mismo
“\r”.
 |
| Figura 5: Trama de red del comando "Get Info" en NetBus |
Tras ver esto quise interactuar con el bicho a través del
script, era como meterle mano al juguete que tenía de pequeño. El código al final era algo así:
 |
| Figura 6: Código para lanzar un Get Info desde Ruby |
Es sencillo, si el
socket está abierto se manda por él el texto
GetInfo con el delimitador
0d al final y esperamos a que
patch.exe nos proporcione la información. Una vez recibida, la damos un poco de format sustituyendo los
";" y
"|" por saltos de línea y después se muestra.
Fase 3: Controlando NetBus con un módulo de Metasploit
Seguí investigando y jugando un poco con el troyano e implementé también la posibilidad de enviar texto a la víctima, recopilar información sobre el disco duro, por ejemplo listar todos los archivos y carpetas, y la posibilidad de ejecutar un
message box en remoto, así que me cree un menú con las opciones de control del troyano que quería implementar y empecé con este proyecto personal de verano para crear un
programa en Ruby para controlar NetBus que podéis descargar desde aquí, aunque como salió el sol por el norte y decidí que las vacaciones eran para coger algo de color y lo dejé para el siguiente día.
 |
| Figura 7: Panel de control para NetBus |
¿Segundo día y también llueve? En efecto, llover y mucho llover por el norte en mis días por allí, por lo que decidí llevar mi pequeño
script al mundo
Metasploit. Mi idea era hacer un
módulo auxiliary, mi prueba de concepto, más didáctico que efectivo en una auditoría, aunque módulos en
Metasploit que detectan
malware o que detectan paneles de gestión existen. Si visualizamos la ruta
modules/auxiliary/scanner/misc podemos encontrar los módulos en
Ruby que comentaba.
Apoyándome en un módulo scanner el cual ya nos proporciona la posibilidad de escanear rangos de direcciones
IP quise implementar la funcionalidad que tenía en mi
script anterior.
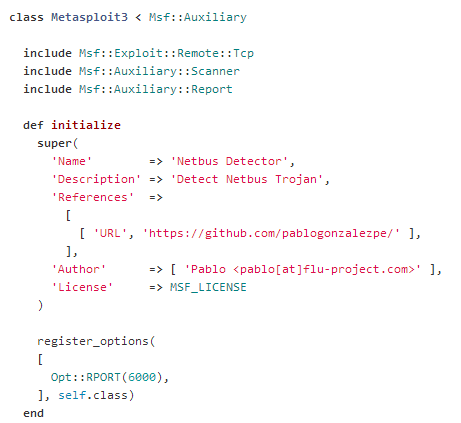 |
| Figura 8: Módulo NetBus Detector para Metasploit |
Es importante observar los
mixins que se incluyen con
Tcp,
scanner y
report. Un
mixin es una llamada a un método que es proporcionado por otra clase y que simplifica las tareas que realizamos. Por ejemplo, en el caso de
Tcp se nos proporciona
connect() y
disconnect(). Con la primera se crea un
socket contra el puerto y dirección
IP que toque, recordemos que un módulo scanner coge rangos de direcciones
IP y mediante un bucle se van recorriendo estas direcciones
IP. El
mixin disconnect() nos permite cerrar el
socket. Más adelante en este artículo se muestra una zona de código dónde se pueden visualizar tanto el
connect() como el
disconnect().
La función
initialize que todo módulo debe incluir permite inicializar el módulo cuando éste es cargado en el
framework. Podemos ver que existen ciertos atributos que se configuran a modo informativo sobre el nombre del módulo, autor, tipo de licencia, etcétera. Esta información puede ser visualizada en
msfconsole a través del comando
info.
 |
| Figura 9: NetBus Detector cómo módulo MetasPloit |
Por último, la función
initialize tiene una llamada importante que es
register_options. Con este método podemos incluir o sobreescribir nuevos atributos o parámetros del módulo. En este caso se indica que el parámetro
RPORT por defecto tiene el valor
6000, que como hemos podido ver es un puerto en el que
NetBus trabaja. Si decides implementar tus módulos utilizarás esta llamada en algún momento.
Al final la otra función que debe tener un módulo de
Metasploit de tipo
auxiliary es la de
run_host. En esta función se le pasa el
target_host, que simplemente será la dirección
IP que toque ser escaneada. En otras palabras, como es un
módulo auxiliary y de tipo scanner, de forma trasparente al programador el
framework le proporciona un bucle que va ejecutando esta función, siendo en cada iteración un
target_host distinto. También otra opción viable es la utilización de un número mayor de
THREADS, ya que por defecto es 1. Esto también es trasparente al programador gracias al
framework, por lo que podemos lanzar distintos hilos que el programador no tendrá que realizar la gestión ni de esto, ni de la llamada a
run_host con distintos valores.
 |
| Figura 10: Código del módulo auxiliary de NetBus Detector |
Como se puede ver en la definición de la función
run_host se abre un
socket a través del
mixin connect. Una vez abierto el
socket se espera que
patch.exe, el bicho de
NetBus nos envíe su versión. Tras esto se imprime la por pantalla que se ha encontrado en una dirección
IP una versión de
NetBus. En este punto se podría utilizar una expresión regular para asegurarnos que lo encontrado es lo que buscábamos.
En el momento que se encuentra una dirección
IP infectada se muestra un menú al usuario para que interactúe con él. A modo de prueba de concepto se han implementado algunas funcionalidades para manejar el troyano.
 |
| Figura 11: El panel de opciones de NetBus Detector para controlar NetBus desde Metasploit |
A continuación podemos ver cómo se puede lanzar un
message box sobre la máquina infectada. Realmente se ha implementado un mini cliente de
NetBus en esta prueba de concepto. Posteriormente se muestra la captura dónde se recibe lo que ha pulsado el usuario víctima.
 |
| Figura 12: Un mensaje enviado con NetBus Detector desde Metasploit |
Por último, quiero mostraros una función interesante como es el listado de ficheros que se encuentran en el disco de la víctima. Tras analizar con
Wireshark cómo realiza esta operación paso a comentarla. El cliente legítimo manda un
“GetFiles” a través del
socket abierto en el puerto
6000, el servidor nos contesta con
“DiskDone” y nos indica un tamaño en
bytes de lo que ocupa toda la información (textual) que recibiremos. Después de esto, el cliente legítimo abre un segundo
socket al puerto
12346 y es dónde tras abrir la conexión se recibe toda la información del disco duro.
 |
| Figura 13: Datos de DiskDone |
Tenéis disponible el código en mi
github NetBus Detector para poder trastear con ello un rato y poder evolucionarlo. Si quieres aprender más sobre
Metasploit y un poco del desarrollo en el
framework os invito a leer "
mi libro" de
Metasploit para pentesters.
Autor: Pablo González Pérez (@pablogonzalezpe)
Escritor del libro "Metasploit para Pentesters"




 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
















































