



 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Cómo se creó ChatGPT: Un hito histórico en la Inteligencia Artificial Conversacional
No dentro de mucho tiempo, habrá asistentes de Inteligencia Artificial específicos para cada uno de los profesionales denominados “trabajadores del conocimiento” (programadores, arquitectos, ingenieros, científicos, abogados, profesores…). Asistentes en los que se delegarán las tareas más repetitivas y comunes, con menos carga cognitiva, y que nos permitirá centrarnos en aquellas más creativas y estratégicas.

En este contexto, gran culpa tendrán las IA conocidas como modelos de lenguaje, concretamente los modelos conversacionales. Estos harán que la interacción que tengamos con ellos sea lo más natural, humana y sencillamente posible, puesto que comprenderán el mismo lenguaje que nosotros, y podremos hablarlos/escribirlos como si estuviésemos tratando con compañeros de trabajo.

Figura 1: Cómo se creó ChatGPT: Un hito histórico en
la Inteligencia Artificial Conversacional
En este contexto, gran culpa tendrán las IA conocidas como modelos de lenguaje, concretamente los modelos conversacionales. Estos harán que la interacción que tengamos con ellos sea lo más natural, humana y sencillamente posible, puesto que comprenderán el mismo lenguaje que nosotros, y podremos hablarlos/escribirlos como si estuviésemos tratando con compañeros de trabajo.
ChatGPT es un gran ejemplo, y ha dado la vuelta al mundo recientemente. Una Inteligencia Artificial Conversacional que ha demostrado de lo que es capaz esta tecnología. Para bien y para mal en el área que afecta a la ciberseguridad, con sus aciertos y sus fallos, y es que se trata de un proyecto que sigue en investigación, en proceso de mejora. De todas maneras, lo que está claro es que ha asentado las bases para lo que se puede venir no dentro de mucho tiempo.
En este artículo quiero explicar el proceso de creación de este modelo conversacional, el más avanzado hasta el momento en nuestra historia, en el que se ha utilizado una técnica que ha estado emergiendo desde hace unos años con gran fuerza: el Aprendizaje por Refuerzo con Intervención Humana.
Funcionamiento
Lo que diferencia a ChatGPT de la anterior familia de modelos de lenguaje de OpenAI como GPT-3 es la aplicación del Aprendizaje Por Refuerzo con Intervención Humana para su entrenamiento y evaluación.

Los creadores no han publicado de manera oficial cómo ha sido entrenado exactamente este chatbot, pero como se puede ver en la página oficial donde podemos probarlo, afirman que han utilizado las mismas técnicas aplicadas para InstructGPT, otro modelo de lenguaje creado por ellos mismos, “con ligeras diferencias en la recolección de datos para su entrenamiento”. De esta manera, vamos a ver a continuación en diferentes pasos como se creó ChatGPT, siguiendo los métodos de creación de InstructGPT.
Paso 1: Fine-tuning de modelo GPT-3.5
En primer lugar, un modelo de lenguaje ya entrenado (como puede ser GPT-3) es fine-tuneado o ajustado con una serie de pocos datos ejemplares recogidos por etiquetadores (personas humanas encargadas de recolección y etiquetado de datos, esencial para el aprendizaje supervisado), obteniendo así el modelo referido como supervised fine-tuning model (modelo SFT). Sin embargo, en vez de haber ajustado GPT-3, los creadores escogieron un modelo de la llamada serie GPT-3.5, se cree que se seleccionó uno que fue ajustado o entrenado aún más en su día mayoritariamente con código de programación.
En cuanto a la recolección de datos para su entrenamiento, se seleccionó una lista de prompts (un prompt es lo que un usuario le introduce al modelo, como por ejemplo “Explícame en qué consiste el aprendizaje por refuerzo”) y a un grupo de etiquetadores humanos se les pidió que escribieran las respuestas de salida deseadas o esperadas. Como resultado, se obtuvo un conjunto de datos de alta calidad, no demasiado grande (el proceso para su obtención llevaba mucho esfuerzo), que se utilizó para ajustar este modelo de lenguaje pre-entrenado que se ha comentado, obteniendo así el modelo SFT.

Como suele ocurrir en este mundo del Deep Learning, al igual que es importante la calidad de los datos, también lo es disponer de una gran cantidad de ellos. Pero como hemos comentado, este paso era costoso (requería de personas humanas teniendo que escribir salidas deseadas por cada prompt escogido), por lo que lo más probable es que las respuestas que generaba el modelo obtenido en este paso no fueran aún demasiado deseables a juicio de un humano.
En este momento, en vez de solicitar a los etiquetadores que crearan un conjunto de datos mucho más grande, lo que se hizo fue que se les encargó clasificar o hacer un ranking de las diferentes salidas que iba generando este modelo, en relación a la calidad de la respuesta generada (intentando que la respuesta fuese lo más humana posible y de calidad) para crear lo que se conoce como un modelo de recompensa (RM).
Paso 2: Entrenamiento de modelo de recompensa (RM)
El objetivo aquí es claro: intentar crear un modelo que aprenda a juzgar al igual que hacían los etiquetadores cada respuesta generada por el modelo SFT a partir de cada prompt de entrada. Es decir, crear un modelo que de manera automática clasifique o dé una puntuación a las salidas de este modelo, teniendo como referencia cómo de esperadas o deseables son estas respuestas para los humanos.
Para la creación de este modelo de recompensa, se escogía de manera iterativa un prompt y varias respuestas que el modelo SFT había generado para ese prompt. Entonces, los etiquetadores clasificaban estas respuestas de mejor a peor, teniendo como resultado un nuevo conjunto de datos etiquetados, donde las propias etiquetas consistían en estas clasificaciones (Aprendizaje Supervisado). Estos nuevos datos son los que se utilizaron para entrenar este modelo de recompensa, cuyo objetivo era recibir como entrada diferentes salidas del modelo SFT del paso 1 y clasificarlos en orden de preferencia.

Para los etiquetadores humanos que se encargaron de este proceso, es mucho más fácil ir clasificando las salidas que tener que ir escribiendo las respuestas que se deseaban, por lo que este proceso fue realizado a una mayor escala de datos.
Paso 3. Optimizando el modelo SFT con Aprendizaje por Refuerzo
En este momento, se aplica Aprendizaje por Refuerzo, y se adapta el problema para ello. En esta área del Aprendizaje Automático, basada en la psicología conductista, se conoce con el concepto de política a la estrategia que lleva a la maximización de los objetivos, con espacio de acciones se conoce al conjunto de “herramientas” que se pueden utilizar, y la función de refuerzo establece la recompensa a generar. De esta manera, el objetivo es aprender una estrategia que maximice la posible recompensa a obtener.
 |
| Figura 2: Libro de Machine Learning aplicado a Ciberseguridad de Carmen Torrano, Fran Ramírez, Paloma Recuero, José Torres y Santiago Hernández |
Funcionamiento
Lo que diferencia a ChatGPT de la anterior familia de modelos de lenguaje de OpenAI como GPT-3 es la aplicación del Aprendizaje Por Refuerzo con Intervención Humana para su entrenamiento y evaluación.
Los creadores no han publicado de manera oficial cómo ha sido entrenado exactamente este chatbot, pero como se puede ver en la página oficial donde podemos probarlo, afirman que han utilizado las mismas técnicas aplicadas para InstructGPT, otro modelo de lenguaje creado por ellos mismos, “con ligeras diferencias en la recolección de datos para su entrenamiento”. De esta manera, vamos a ver a continuación en diferentes pasos como se creó ChatGPT, siguiendo los métodos de creación de InstructGPT.
Paso 1: Fine-tuning de modelo GPT-3.5
En primer lugar, un modelo de lenguaje ya entrenado (como puede ser GPT-3) es fine-tuneado o ajustado con una serie de pocos datos ejemplares recogidos por etiquetadores (personas humanas encargadas de recolección y etiquetado de datos, esencial para el aprendizaje supervisado), obteniendo así el modelo referido como supervised fine-tuning model (modelo SFT). Sin embargo, en vez de haber ajustado GPT-3, los creadores escogieron un modelo de la llamada serie GPT-3.5, se cree que se seleccionó uno que fue ajustado o entrenado aún más en su día mayoritariamente con código de programación.
En cuanto a la recolección de datos para su entrenamiento, se seleccionó una lista de prompts (un prompt es lo que un usuario le introduce al modelo, como por ejemplo “Explícame en qué consiste el aprendizaje por refuerzo”) y a un grupo de etiquetadores humanos se les pidió que escribieran las respuestas de salida deseadas o esperadas. Como resultado, se obtuvo un conjunto de datos de alta calidad, no demasiado grande (el proceso para su obtención llevaba mucho esfuerzo), que se utilizó para ajustar este modelo de lenguaje pre-entrenado que se ha comentado, obteniendo así el modelo SFT.

Figura 4: Resumen gráfico del paso 1
Como suele ocurrir en este mundo del Deep Learning, al igual que es importante la calidad de los datos, también lo es disponer de una gran cantidad de ellos. Pero como hemos comentado, este paso era costoso (requería de personas humanas teniendo que escribir salidas deseadas por cada prompt escogido), por lo que lo más probable es que las respuestas que generaba el modelo obtenido en este paso no fueran aún demasiado deseables a juicio de un humano.
En este momento, en vez de solicitar a los etiquetadores que crearan un conjunto de datos mucho más grande, lo que se hizo fue que se les encargó clasificar o hacer un ranking de las diferentes salidas que iba generando este modelo, en relación a la calidad de la respuesta generada (intentando que la respuesta fuese lo más humana posible y de calidad) para crear lo que se conoce como un modelo de recompensa (RM).
Paso 2: Entrenamiento de modelo de recompensa (RM)
El objetivo aquí es claro: intentar crear un modelo que aprenda a juzgar al igual que hacían los etiquetadores cada respuesta generada por el modelo SFT a partir de cada prompt de entrada. Es decir, crear un modelo que de manera automática clasifique o dé una puntuación a las salidas de este modelo, teniendo como referencia cómo de esperadas o deseables son estas respuestas para los humanos.
Para la creación de este modelo de recompensa, se escogía de manera iterativa un prompt y varias respuestas que el modelo SFT había generado para ese prompt. Entonces, los etiquetadores clasificaban estas respuestas de mejor a peor, teniendo como resultado un nuevo conjunto de datos etiquetados, donde las propias etiquetas consistían en estas clasificaciones (Aprendizaje Supervisado). Estos nuevos datos son los que se utilizaron para entrenar este modelo de recompensa, cuyo objetivo era recibir como entrada diferentes salidas del modelo SFT del paso 1 y clasificarlos en orden de preferencia.

Figura 4: Resumen gráfico del paso 2
Para los etiquetadores humanos que se encargaron de este proceso, es mucho más fácil ir clasificando las salidas que tener que ir escribiendo las respuestas que se deseaban, por lo que este proceso fue realizado a una mayor escala de datos.
Paso 3. Optimizando el modelo SFT con Aprendizaje por Refuerzo
En este momento, se aplica Aprendizaje por Refuerzo, y se adapta el problema para ello. En esta área del Aprendizaje Automático, basada en la psicología conductista, se conoce con el concepto de política a la estrategia que lleva a la maximización de los objetivos, con espacio de acciones se conoce al conjunto de “herramientas” que se pueden utilizar, y la función de refuerzo establece la recompensa a generar. De esta manera, el objetivo es aprender una estrategia que maximice la posible recompensa a obtener.
En este contexto, entendemos como política a una “copia” del modelo de lenguaje SFT obtenido en el paso 1 (a esta copia la referimos como modelo PPO, pues este es el algoritmo que se utilizará para actualizar esta política), con espacio de acciones al vocabulario del modelo (todas las palabras, símbolos… que reconoce ChatGPT), cuya combinación forma todo el espacio observable, mientras que la función de refuerzo es una combinación de la salida del modelo de recompensa (RM) del paso 2 con una restricción sobre cómo aplicar cambios en la política, que explicaremos posteriormente.
Este modelo PPO se va actualizando de manera iterativa, de la siguiente manera. Se escoge un prompt del conjunto de datos y se hace una “copia” del modelo STF del paso 1 (esto solo se realiza la primera vez dentro de este algoritmo), teniendo así el modelo PPO, que constituye nuestra política. Con esta política se genera una respuesta a ese prompt y se le pasa esta al modelo de recompensa (RM) entrenado en el paso 2, obteniendo un número escalar, con su clasificación o puntuación de deseabilidad, que mide cómo se ajusta esta a las necesidades de un humano.
Este modelo PPO se va actualizando de manera iterativa, de la siguiente manera. Se escoge un prompt del conjunto de datos y se hace una “copia” del modelo STF del paso 1 (esto solo se realiza la primera vez dentro de este algoritmo), teniendo así el modelo PPO, que constituye nuestra política. Con esta política se genera una respuesta a ese prompt y se le pasa esta al modelo de recompensa (RM) entrenado en el paso 2, obteniendo un número escalar, con su clasificación o puntuación de deseabilidad, que mide cómo se ajusta esta a las necesidades de un humano.
Esta puntuación se va a introducir como entrada de la función de refuerzo, pero no solo eso, ya que como comentamos anteriormente, se introduce también una restricción sobre cómo o cuánto actualizar la política (además, sin entrar en detalle, también se introduce otro tercer parámetro que garantiza un mejor funcionamiento, mediante una técnica conocida como pre-training mix).

En realidad, dado el prompt escogido, aparte de generar una respuesta con nuestra política, también generamos una respuesta con el modelo SFT inicial, sobre el que se copió o inicializó nuestra política. Entonces, se calcula esta restricción con una técnica llamada de penalización (conocida como KL-Penalty) que recibe los textos generados por el modelo SFT original y por la política, cuyo objetivo es calcular una diferencia entre ellos, para que la política no genere texto incoherente pero que pueda engañar y dar una recompensa alta, de esta manera se garantiza que las respuestas sean vistas de manera más humana pero también con la coherencia con la que se generaban en el modelo inicial
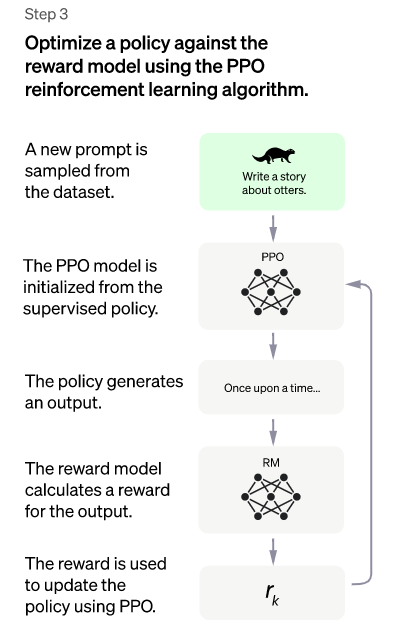
Figura 5: Resumen gráfico del paso 3
En realidad, dado el prompt escogido, aparte de generar una respuesta con nuestra política, también generamos una respuesta con el modelo SFT inicial, sobre el que se copió o inicializó nuestra política. Entonces, se calcula esta restricción con una técnica llamada de penalización (conocida como KL-Penalty) que recibe los textos generados por el modelo SFT original y por la política, cuyo objetivo es calcular una diferencia entre ellos, para que la política no genere texto incoherente pero que pueda engañar y dar una recompensa alta, de esta manera se garantiza que las respuestas sean vistas de manera más humana pero también con la coherencia con la que se generaban en el modelo inicial
En este último momento, con la recompensa que genera la función de refuerzo recibiendo la clasificación de deseabilidad, generada por el modelo RM recibiendo como entrada la respuesta generada por la política al prompt, y la penalización (además del tercer parámetro ya mencionado), se actualizará esta política, es decir, el modelo PPO. Esto se hará de manera iterativa hasta que se finalice el entrenamiento, con el objetivo de optimizar la política (generar cada vez mejor un modelo de lenguaje de calidad y “más humano”).
Conclusiones
Durante la fase de evaluación del rendimiento de ChatGPT, donde también una serie de personas humanas analizaban las respuestas generadas por este modelo con prompts provenientes del conjunto de test, no vistos durante el entrenamiento, se juzgaba que fueran respuestas útiles, veraces e inofensivas.
Conclusiones
Durante la fase de evaluación del rendimiento de ChatGPT, donde también una serie de personas humanas analizaban las respuestas generadas por este modelo con prompts provenientes del conjunto de test, no vistos durante el entrenamiento, se juzgaba que fueran respuestas útiles, veraces e inofensivas.
Hemos visto que en muchos casos evita hablar de ciertos temas y otros en los que lo hace y no debería, que puede pecar de alucinaciones (es como se conoce a la generación de hechos falsos) y, también, dar muchas respuestas útiles.
Sigue en fase de investigación, y nosotros estamos siendo parte de su mejora futura (podemos aportar feedback sobre las respuestas que genera, tanto para bien como para mal). Yo, personalmente, aun sabiendo que no siempre es perfecto en sus respuestas, me estoy divirtiendo mucho con su uso, y seguramente no sea el único.





















