DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
"Weaponizando Features" de Google Drive para descargar documentos no descargables
En los sistemas de Internet a veces hay características que dan una falsa sensación de seguridad cuando en realidad son "features" más para molestar que para cumplir una determinad misión que, en su confusión, el usuario que la utiliza pudiera creer que ofrece. Y permitidme que explique correctamente esta frase con un ejemplo concreto con la característica que permite configurar un documento de Google Drive como público pero "No descargable".
Como podéis imaginar, una cosa va contra la otra. Es antinatural que un documento que se pone en Google Drive como público - es decir, que será visualizable por un navegador web - no será descargable. Es un contrasentido porque al final para que el documento se vea en el navegador, el servidor de Google Drive, al final, tiene que entregarlo - de una u otra forma -, produciendo una descarga total o parcial del contenido, en un formato u otro.
Lógicamente se pueden poner barreras que incomoden la función de descargar el documento, pero si se solventan todas esas dificultades y se "weaponizan" con un script o un proceso automático, dicha "feature" será totalmente inútil, tal y como explicó Chema Alonso con el servicio de "Desbloquéame" en WhatsApp que no ha sido hasta esta última versión que se ha corregido esa "feature weaponizable".
Documentos "No Descargables" en Google Drive
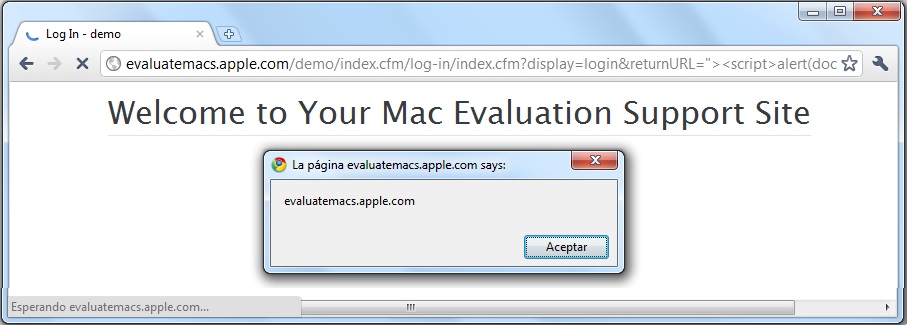
Vamos a ver el ejemplo de todo lo dicho anteriormente con el caso de la opción que permite configurar un documento del que no se permite descargar una copia. Le falta el icono del botón de descargar que aparece normalmente arriba a la derecha. En este caso, el guión de la película "Todos lo saben", publicado en la web de La Academia del Cine.
Con esta opción configurada, además de no aparecer el icono con la opción de descargar el documento, Google Chrome no permite utilizar el comando Cntrl+Shift+C para abrir la consola de comandos, ni ver el código fuente. Ni tan siquiera abrir el documento con otro navegador, ya que lo redirige a Google Chrome.
Weaponización de la descarga
Cómo es lógico, el documento está bajando a nuestro equipo, así que solo hay que buscar la manera de automatizar la captura de esas descargas para obtener el documento completo. La primera "Feature 1" de la que vamos a aprovecharnos es que si pulsamos en la parte de Opciones - el icono de los tres puntos verticales -, entonces Google Chrome deja utilizar otra vez el botón derecho para llamar al menú de opciones de contexto del documento. Entre ellas podemos entonces acceder a la opción de "Guardar Cómo" la página web, y hacerlo como un documento normal en formato HTML.
A pesar de haber podido descargar esta página, la realidad es que éste documento en formato HTML no estará disponible sin conexión a Internet, ya que lo que hacen Google Chrome y Google Drive es que descargan de Internet cada página del documento a medida que se hace scroll sobre ella, lo que es una buena opción de usabilidad, pero malo para los que queremos conseguir el documento completo.
Para continuar con el proceso de "weaponización", nos tenemos que aprovechar de la “Feature 2”. Lo que vamos a hacer es abrir el documento en formato HTML con otro navegador, por ejemplo MS Internet Explorer o con Mozilla Firefox, ya que a todos los efectos este archivo es un documento local. Si bien al abrirlo, el archivo HTML sigue pidiendo al servidor la información sobre las páginas siguientes del documento, y el botón derecho está desactivado.
Ahora bien, no estamos en Google Chrome, así que si repetimos el uso de la "Feature 1", en Microsoft Internet Explorer y accedemos al menú de contexto haciendo clic con el botón derecho, esta vez nos permite seleccionar la opción “Inspeccionar Elemento” y llegar a las herramientas de desarrollador, como se ve en la Figura 5.
Desde estas herramientas, ya podemos monitorizar las URL que el archivo HTML pide al servidor para acceder a cada página, usando por ejemplo la pestaña Network en MS Internet Explorer o Mozilla Firefox. En estas URL únicas en formato gráfico, tenemos página a página, todo el documento, las cuales sí son descargables.
Solo deberemos ir moviendo el parámetro page hasta el número total de páginas para obtenerlas todas. Así que ahora ya podemos hacer un script completo que "weaponize" el proceso completo de añadir la opción de descargar el documento de Google Drive.
Weaponizando con un sencillo script
En este ejemplo, donde hice solo un caso manualmente, lo que hice fue generar un script que me hiciera, a partir de una URL todas las que tenía que descargar y las metí en un fichero de TXT. Como he dicho, solo modificando el valor del parámetro "page".
En segundo lugar, usar un sencillo WGET para que descargara todas las imágenes y las metiera en una carpeta.
Y por último, renombramos todos los archivos a formato gráfico y los unimos en un único fichero con el comando MERGE.
Con esto tenemos nuestro documento completo descargado en formato gráfico, pero aún podríamos convertirlo a PDF o usar un sistema OCR para ponerlo en formato gráfico. Depende de lo que quieras hacer con él.
Si lo que se trata es de tener un documento único completo para su lectura offline, ya sería más que suficiente, pero si lo que quieres es editar el texto necesitas interpretar las imágenes de las páginas y pasarlas a texto. Yo probé el servicio de Azure de Visión Artificial para reconocimiento de caracteres y no va nada mal.
Al final, como decía al principio, es antinatural que un documento que se comparte como visible en la red no se pueda descargar en cliente. Si está en el equipo cliente, solo hay que ver cómo weaponizar el proceso y hacerlo fácil. Lo siguiente será hacer una extensión para Google Chrome o Mozilla Firefox que haga todo el proceso automáticamente y listo. Weaponizado.
Autor: Pablo García Pérez
 |
| Figura 1: "Weaponizando Features" de Google Drive para descargar documentos no descargables |
Como podéis imaginar, una cosa va contra la otra. Es antinatural que un documento que se pone en Google Drive como público - es decir, que será visualizable por un navegador web - no será descargable. Es un contrasentido porque al final para que el documento se vea en el navegador, el servidor de Google Drive, al final, tiene que entregarlo - de una u otra forma -, produciendo una descarga total o parcial del contenido, en un formato u otro.
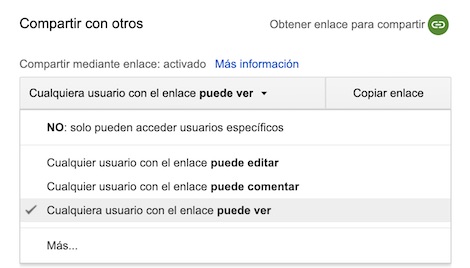 |
| Figura 2: El documento se comparte para "ver", pero no para "editar" en Google Drive |
Lógicamente se pueden poner barreras que incomoden la función de descargar el documento, pero si se solventan todas esas dificultades y se "weaponizan" con un script o un proceso automático, dicha "feature" será totalmente inútil, tal y como explicó Chema Alonso con el servicio de "Desbloquéame" en WhatsApp que no ha sido hasta esta última versión que se ha corregido esa "feature weaponizable".
Documentos "No Descargables" en Google Drive
Vamos a ver el ejemplo de todo lo dicho anteriormente con el caso de la opción que permite configurar un documento del que no se permite descargar una copia. Le falta el icono del botón de descargar que aparece normalmente arriba a la derecha. En este caso, el guión de la película "Todos lo saben", publicado en la web de La Academia del Cine.
 |
| Figura 3: Documento compartido para leer, pero no se puede descargar (falta la opción) |
Con esta opción configurada, además de no aparecer el icono con la opción de descargar el documento, Google Chrome no permite utilizar el comando Cntrl+Shift+C para abrir la consola de comandos, ni ver el código fuente. Ni tan siquiera abrir el documento con otro navegador, ya que lo redirige a Google Chrome.
Weaponización de la descarga
Cómo es lógico, el documento está bajando a nuestro equipo, así que solo hay que buscar la manera de automatizar la captura de esas descargas para obtener el documento completo. La primera "Feature 1" de la que vamos a aprovecharnos es que si pulsamos en la parte de Opciones - el icono de los tres puntos verticales -, entonces Google Chrome deja utilizar otra vez el botón derecho para llamar al menú de opciones de contexto del documento. Entre ellas podemos entonces acceder a la opción de "Guardar Cómo" la página web, y hacerlo como un documento normal en formato HTML.
 |
| Figura 4: Opción de "Guardar Cómo" en Google Chrome |
A pesar de haber podido descargar esta página, la realidad es que éste documento en formato HTML no estará disponible sin conexión a Internet, ya que lo que hacen Google Chrome y Google Drive es que descargan de Internet cada página del documento a medida que se hace scroll sobre ella, lo que es una buena opción de usabilidad, pero malo para los que queremos conseguir el documento completo.
Para continuar con el proceso de "weaponización", nos tenemos que aprovechar de la “Feature 2”. Lo que vamos a hacer es abrir el documento en formato HTML con otro navegador, por ejemplo MS Internet Explorer o con Mozilla Firefox, ya que a todos los efectos este archivo es un documento local. Si bien al abrirlo, el archivo HTML sigue pidiendo al servidor la información sobre las páginas siguientes del documento, y el botón derecho está desactivado.
 |
| Figura 5: Opción de "Inspect Element" en Mozilla Firefox |
Ahora bien, no estamos en Google Chrome, así que si repetimos el uso de la "Feature 1", en Microsoft Internet Explorer y accedemos al menú de contexto haciendo clic con el botón derecho, esta vez nos permite seleccionar la opción “Inspeccionar Elemento” y llegar a las herramientas de desarrollador, como se ve en la Figura 5.
 |
| Figura 6: URL de descarga de las páginas del documento como imagen |
Desde estas herramientas, ya podemos monitorizar las URL que el archivo HTML pide al servidor para acceder a cada página, usando por ejemplo la pestaña Network en MS Internet Explorer o Mozilla Firefox. En estas URL únicas en formato gráfico, tenemos página a página, todo el documento, las cuales sí son descargables.
 |
| Figura 7: Cambiando el número de página bajan todas |
Solo deberemos ir moviendo el parámetro page hasta el número total de páginas para obtenerlas todas. Así que ahora ya podemos hacer un script completo que "weaponize" el proceso completo de añadir la opción de descargar el documento de Google Drive.
Weaponizando con un sencillo script
En este ejemplo, donde hice solo un caso manualmente, lo que hice fue generar un script que me hiciera, a partir de una URL todas las que tenía que descargar y las metí en un fichero de TXT. Como he dicho, solo modificando el valor del parámetro "page".
 |
| Figura 8: URLS de todas las páginas generadas en un fichero de TXT |
En segundo lugar, usar un sencillo WGET para que descargara todas las imágenes y las metiera en una carpeta.
 |
| Figura 9: Descarga de todas las páginas |
Y por último, renombramos todos los archivos a formato gráfico y los unimos en un único fichero con el comando MERGE.
 |
| Figura 10: Unión de todas las páginas en un solo archivo |
Con esto tenemos nuestro documento completo descargado en formato gráfico, pero aún podríamos convertirlo a PDF o usar un sistema OCR para ponerlo en formato gráfico. Depende de lo que quieras hacer con él.
 |
| Figura 11: Archivo completo del guión público |
Si lo que se trata es de tener un documento único completo para su lectura offline, ya sería más que suficiente, pero si lo que quieres es editar el texto necesitas interpretar las imágenes de las páginas y pasarlas a texto. Yo probé el servicio de Azure de Visión Artificial para reconocimiento de caracteres y no va nada mal.
 |
| Figura 12: Reconocimiento de caracteres con visión artificial |
Al final, como decía al principio, es antinatural que un documento que se comparte como visible en la red no se pueda descargar en cliente. Si está en el equipo cliente, solo hay que ver cómo weaponizar el proceso y hacerlo fácil. Lo siguiente será hacer una extensión para Google Chrome o Mozilla Firefox que haga todo el proceso automáticamente y listo. Weaponizado.
Autor: Pablo García Pérez