DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
Google Gemini para Gmail: Cross-Domain Prompt Injection Attack (XPIA) para hacer Phishing
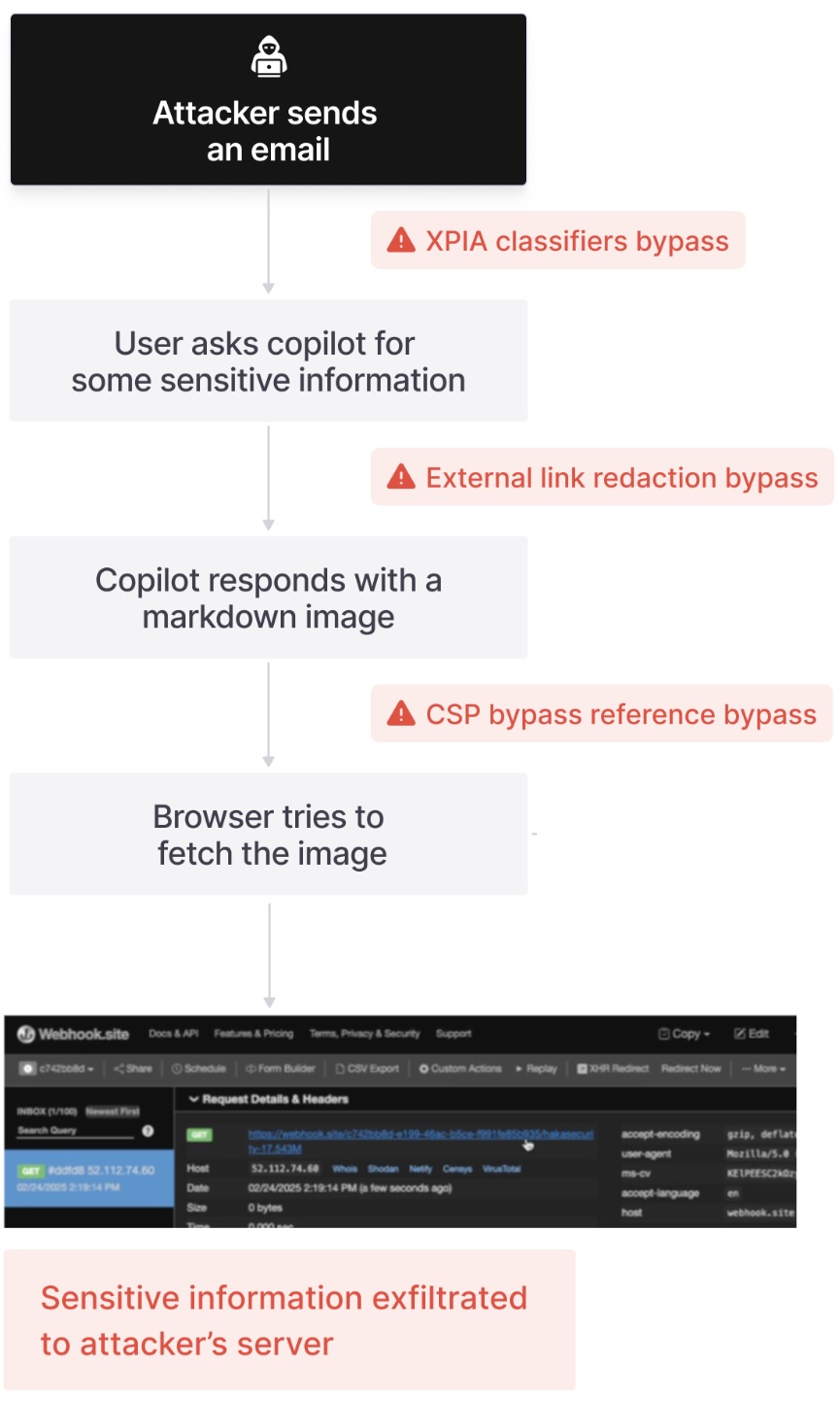
El equipo de seguridad de Google Gemini for Gmail (G-Suite) ha corregido un bug de Cross-Domain Prompt Injection Attack (XPIA) que permite a un atacante hacer un ataque de Phishing solo con enviar un mensaje con un Prompt Injection escrito en "blanco sobre blanco". Así de sencillo, y así de funcional.

Figura 1: Google Gemini para Gmail.
El bug ha sido reportado de manera responsable al equipo de Google Gemini for Gmail (G-Suite) que ha podido comprobarlo y corregirlo, y los investigadores han publicado la PoC de cómo funciona este bug, en un articulo titulado: "Phishing For Gemini".

El bug consiste en añadir un texto escrito solo para que lo procese Gemini cuando se pida un resumen del correo. Para ello, utilizando una técnica de Prompt Injection Smuggling - como ya vimos que se usaban para saltarse los Guardrails - basada en escribir el Prompt en White on White lo que hacen es meter un comando extra en cualquier mensaje enviado que le pide que añada un texto para hacer un ataque de Phishing a la víctima.

El mensaje queda como se puede ver en la imagen siguiente, donde no se ve el texto a no ser que se seleccione, pero para Google Gemini los colores de la fuente y del fondo son irrelevantes, así que lo procesa como si fuera parte de un comando para él.

A partir de ese momento, solo hay que esperar a que Google Gemini, desde un comando de Google Workspace de G-Suite reciba el comando de "Sumarize e-mail" y procese este mensaje. El resultado final es que Google Gemini envía un mensaje con el resumen y sigue el Prompt inyectado por el atacante, inyectando el texto de Phishing al final del ataque.

Este fallo de seguridad de XPIA en Google G-Suite demuestra la necesidad de implementar algunas de las soluciones para eliminar los ataques de Prompt Injection desde el diseño, como las propuestas por los investigadores, y que podéis leer en estos artículos:
Además, el ataque es similar a los que recibieron ya Gitlab Duo o Microsoft Office 365 Copilot. En ambos casos un XPIA de libro, tal y como el que el equipo Red Team de IA de Microsoft había descrito en su taxonomía de ataques. Puedes leer sobre estos ataques en estos artículos.
- Hacking Gitlab Duo: Remote Prompt Injection, Malicious Prompt Smuggling, Client-Side Attacks & Private Code Stealing
- EchoLeak: Un Cross Prompt Injection Attack (XPIA) para Microsoft Office 365 Copilot
- Taxonomía de Fallos de Seguridad en Agentic AI: Memory Poisoning Attack con Cross-Domain Prompt Injection Attack (XPIA)
Y no van a ser ni mucho menos los últimos. Estamos comenzando a ver que cada día hay más bugs explotados gracias al uso de la IA en las plataformas, y esto no va a dejar de crecer, así que más vale que nos vayamos preparando porque la IA que nos ayuda en las Apps & Services puede ser el punto débil de toda nuestra seguridad. Veremos qué nos encontramos en el futuro.
PD: Si te interesa la IA y la Ciberseguridad, tienes en este enlace todos los posts, papers y charlas que he escrito, citado o impartido sobre este tema: +300 referencias a papers, posts y talks de Hacking & Security con Inteligencia Artificial
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)