




 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
"Colega, ¿dónde está mi moto?". Cómo reconocer motos por su sonido con Inteligencia Artificial
A nuestro compañero Fernando Guillot le robaron su moto. Nunca la recuperó. En una conversación con Chema Alonso comentó que ahora cada vez que oía una moto como la suya se giraba y que estaba todo el día buscándola entre el tráfico. "¿Reconoces tu moto por el sonido del motor?", preguntó Chema Alonso. "Claro", dijo Fernando Guillot, "tiene un sonido muy personal". Y la reflexión de nuestro querido jefe fue que si una persona tienen esa capacidad cognitiva, el equipo de Ideas Locas podía trabajar en una IA que tuviera capacidades cognitivas de reconocimiento de sonidos, que pudiéramos utilizar en sistemas de seguridad, herramientas accesibilidad o entretenimiento. Y aquí entró nuestro proyecto. Spolier: No hemos recuperado la moto de Fer.

Figura 1: "Colega, ¿dónde está mi moto?". Cómo reconocer
motos por su sonido con Inteligencia Artificial
El primer objetivo del proyecto era que una Inteligencia Artificial puediera diferenciar entre distintos sonidos de motos. En Ideas Locas se potencia mucho el Think Out of the Box, por lo que el pensamiento lateral de cómo pensamos que se debe procesar el audio, os va a gustar. Pero para ello, nos debemos arremangar y entender conceptos de procesamiento de señal o Signal Processing, empezando por la Transformada de Fourier (TF). A los Ingenieros de Telecomunicaciones nos ha acompañado durante toda la carrera la siguiente fórmula:

Con esta transformación somos capaces de modelar una señal de entrada - f(t) en nuestro caso, un sonido de una moto - en una composición de tonos de distinta frecuencia y potencia F(w). Por lo que tenemos una señal compleja, sea cual sea, en una superposición de señales básicas, y a partir de esas señales básicas podemos analizar si un sonido proviene o no de un humano, si es más probable de que sea de un hombre o una mujer, o sí la persona que está detrás del micrófono de tu teléfono eres o no tu (biometría por voz). Cuando se trata de una señal digital, como es nuestro caso, se aplica la Discrete Fourier Transform.
El siguiente concepto es el espectrograma. Un espectrograma se consigue a partir del cálculo del espectro de una señal de entrada aplicándole una ventana deslizante - típicamente una ventana de Hann o de Hamming - con un método llamado Short-time Fourier Transform o STFT. Veamos una imagen de la ventana deslizante:

Es decir, de las muestras de nuestra señal de entrada, vamos escogiendo N muestras ponderadas, avanzando en cada iteración, normalmente N/2 posiciones, hasta llegar al final de nuestro vector de entrada. A grandes rasgos, y sabiendo que no seré técnicamente preciso, se trata de aplicar la transformada anterior en segmentos cortos de nuestra señal de entrada, para conseguir así una imagen de las frecuencias presentes en ella. Veamos un ejemplo:

Aunque parece muy abstracto, os recomiendo que juguéis un poco con el Chrome Music Lab, una herramienta muy divertida para el cálculo del espectrograma en tiempo real. Ahí tenéis distintos sonidos pre-grabados, o podéis cantar y ver qué tan agudo/grave es tu voz:

Y aquí es donde viene el pensamiento lateral que se utiliza en nuestro procesamiento de audio: en vez de tratar de diferenciar la señal de entrada a partir de la propia señal, hacemos un clasificador de los distintos espectrogramas, es decir, de imágenes. Veamos dos ejemplos de dos motos distintas y analizamos sus espectrogramas calculados con la librería Librosa.


Como observamos, en el eje de las abscisas se encuentran los distintos instantes en los que se evalúa la señal y en nuestro caso utilizamos chunks de 5 segundos. En el eje de las ordenadas, encontramos una escala de frecuencias desde 0Hz a más de 10kHz, siendo los tonos graves de baja frecuencia y los agudos los de más alta frecuencia. Por ejemplo, y como era de esperar, entre una Vespa y una Yamaha, la Vespa tiene muchas más componentes frecuenciales en altas frecuencias. Los colores los tenemos que interpretar como un mapa de calor, donde a más rojizo más potencia de ese tono frecuencial en el instante "t".
Recogimos de Internet distintos vídeos con sonidos de motos, pero no eran suficientes para entrenar un modelo entero de Deep Learning, dado que estos suelen necesitar del orden de miles de datos para tener buenos resultados, aunque uno haga Transfer Learning. Entonces, utilizando un algoritmo pre-entrenado de reconocimiento de imágenes, podemos sacar las "features" más importantes de cada uno de los espectrogramas y clasificar éstas. Las "features" son las distintas características clave que una red neuronal aprende durante el entreno para realizar su tarea, y nos quedamos con la salida de la última capa antes de la Fully Connected Network, también conocidas como High-Level Features.

Una vez hemos sacado nuestras "features" de todos los datos de entreno, debemos entrenar un clasificador Support Vector Machine (SVM) de estas "features". El SVM, para los que no lo conozcáis, es un algoritmo supervisado de Machine Learning - como algunos de los que se utilizan en los casos de ciberseguridad - para la separación de unos datos de entrenamiento en dos clases a partir de un conjunto de hiperplanos. SVM no necesitan de muchos datos para obtener buenos resultados.
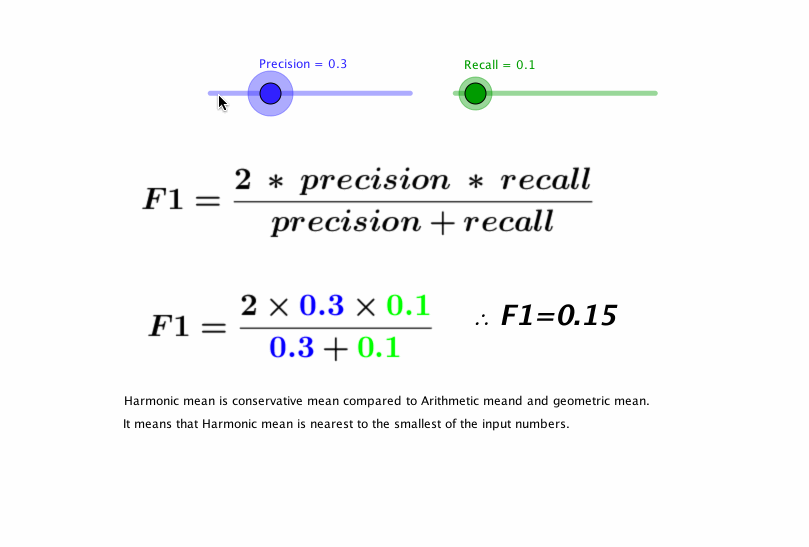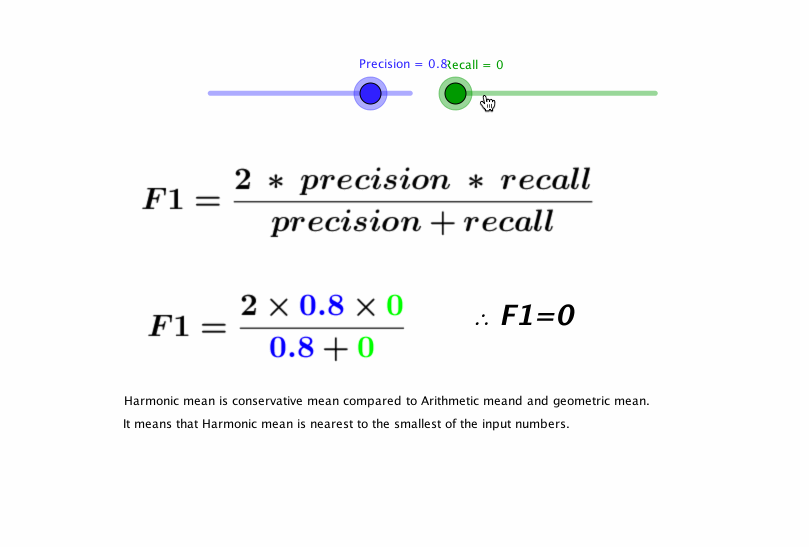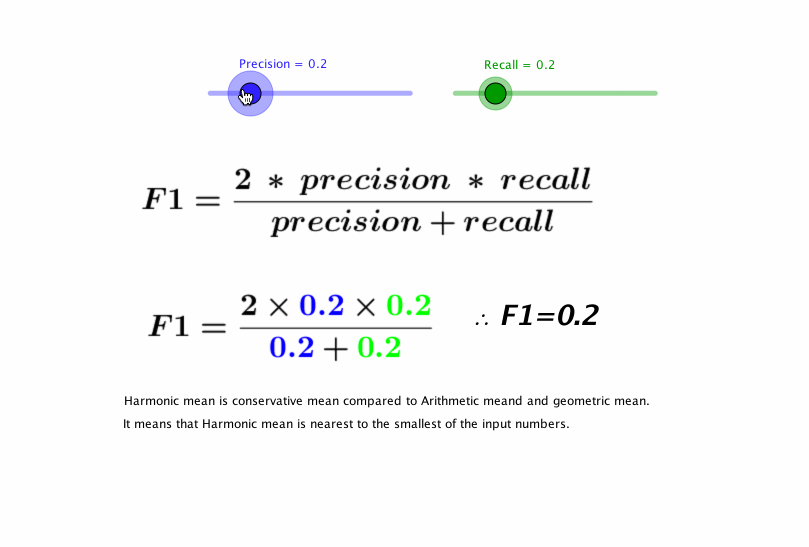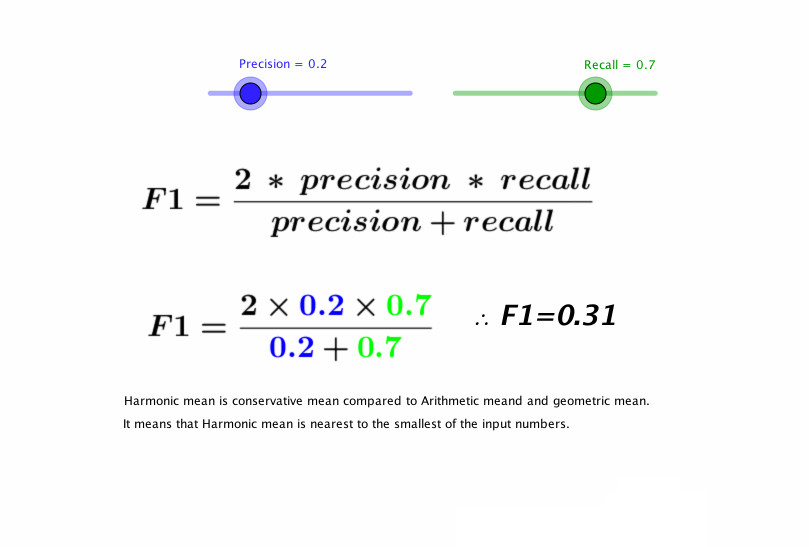
Dado que hay muchos tipos de sonidos de motos distintos, quisimos primero comprobar que se podría verificar si una señal de entrada correspondía o no a un sonido de un modelo concreto de moto. Entrenamos un clasificador binario entre un modelo de Yamaha y el resto de los modelos, teniendo en cuenta que deben estar todas igualmente representadas. Para evaluar un modelo utilizamos el Precision y Recall. Estas dos métricas se deben entender bien y ahora veremos porqué fue clave en nuestro proyecto.

Con esta transformación somos capaces de modelar una señal de entrada - f(t) en nuestro caso, un sonido de una moto - en una composición de tonos de distinta frecuencia y potencia F(w). Por lo que tenemos una señal compleja, sea cual sea, en una superposición de señales básicas, y a partir de esas señales básicas podemos analizar si un sonido proviene o no de un humano, si es más probable de que sea de un hombre o una mujer, o sí la persona que está detrás del micrófono de tu teléfono eres o no tu (biometría por voz). Cuando se trata de una señal digital, como es nuestro caso, se aplica la Discrete Fourier Transform.
El siguiente concepto es el espectrograma. Un espectrograma se consigue a partir del cálculo del espectro de una señal de entrada aplicándole una ventana deslizante - típicamente una ventana de Hann o de Hamming - con un método llamado Short-time Fourier Transform o STFT. Veamos una imagen de la ventana deslizante:

Figura 3: Ejemplo de Sliding Window
Es decir, de las muestras de nuestra señal de entrada, vamos escogiendo N muestras ponderadas, avanzando en cada iteración, normalmente N/2 posiciones, hasta llegar al final de nuestro vector de entrada. A grandes rasgos, y sabiendo que no seré técnicamente preciso, se trata de aplicar la transformada anterior en segmentos cortos de nuestra señal de entrada, para conseguir así una imagen de las frecuencias presentes en ella. Veamos un ejemplo:

Aunque parece muy abstracto, os recomiendo que juguéis un poco con el Chrome Music Lab, una herramienta muy divertida para el cálculo del espectrograma en tiempo real. Ahí tenéis distintos sonidos pre-grabados, o podéis cantar y ver qué tan agudo/grave es tu voz:

Y aquí es donde viene el pensamiento lateral que se utiliza en nuestro procesamiento de audio: en vez de tratar de diferenciar la señal de entrada a partir de la propia señal, hacemos un clasificador de los distintos espectrogramas, es decir, de imágenes. Veamos dos ejemplos de dos motos distintas y analizamos sus espectrogramas calculados con la librería Librosa.

Figura 6: Espectrograma de una Yamaha con Librosa y Matplotlib

Figura 7: Espectrograma de una Vespa con Librosa y Matplotlib
Como observamos, en el eje de las abscisas se encuentran los distintos instantes en los que se evalúa la señal y en nuestro caso utilizamos chunks de 5 segundos. En el eje de las ordenadas, encontramos una escala de frecuencias desde 0Hz a más de 10kHz, siendo los tonos graves de baja frecuencia y los agudos los de más alta frecuencia. Por ejemplo, y como era de esperar, entre una Vespa y una Yamaha, la Vespa tiene muchas más componentes frecuenciales en altas frecuencias. Los colores los tenemos que interpretar como un mapa de calor, donde a más rojizo más potencia de ese tono frecuencial en el instante "t".
Recogimos de Internet distintos vídeos con sonidos de motos, pero no eran suficientes para entrenar un modelo entero de Deep Learning, dado que estos suelen necesitar del orden de miles de datos para tener buenos resultados, aunque uno haga Transfer Learning. Entonces, utilizando un algoritmo pre-entrenado de reconocimiento de imágenes, podemos sacar las "features" más importantes de cada uno de los espectrogramas y clasificar éstas. Las "features" son las distintas características clave que una red neuronal aprende durante el entreno para realizar su tarea, y nos quedamos con la salida de la última capa antes de la Fully Connected Network, también conocidas como High-Level Features.

Una vez hemos sacado nuestras "features" de todos los datos de entreno, debemos entrenar un clasificador Support Vector Machine (SVM) de estas "features". El SVM, para los que no lo conozcáis, es un algoritmo supervisado de Machine Learning - como algunos de los que se utilizan en los casos de ciberseguridad - para la separación de unos datos de entrenamiento en dos clases a partir de un conjunto de hiperplanos. SVM no necesitan de muchos datos para obtener buenos resultados.
 |
| Figura 9: Libro de Machine Learning aplicado a Ciberseguridad de Carmen Torrano, Fran Ramírez, Paloma Recuero, José Torres y Santiago Hernández |

Figura 10: Cálculo de Precision-Recall
En la primera imagen vemos un plano bidimensional con dos clases (verde y roja). Como vemos en la imagen superior, la precisión vendría a ser cuántos hemos acertado en la clasificación (True Positives) respecto al total de los clasificados como ésa clase (True Positives + False Positives), y el recall es cuántos hemos acertado en la clasificación (True Positives) respecto al total de esa clase (True Positives + False Negatives). Por lo tanto, y si debemos realmente analizar qué bien o mal funciona un algoritmo, no nos basta con mirar o la precisión o el recall: debemos mirar los dos y a la vez, y para eso tenemos el F1-score, que se calcula:

En nuestro primer experimento obtuvimos los siguientes resultados, que como podemos ver con la imagen siguiente, tenemos la matriz Precision-Recall para clase 0 (other motorbikes) y clase 1 (Yamaha). Un 92% de clasificación está muy bien para la clase 0, ¿pero por qué el Recall de la clase 1 era tan bajo? Sencillo: balanceo de datos.

Figura 12: Matriz Precision-Recall y F1 Score para el primer experimento
Como era normal, hicimos la recopilación de datos con muchos más vídeos de clase 0 que clase 1. Al final, la clase 0 se trataba de recopilar vídeos de cualquier otra motocicleta que no fuera una Yamaha, obteniendo más de 500 de ellos. El SVM por tanto aprendía a ser más flexible en la clasificación de la clase 0, dado que estaban sobre-representados. Realizamos el mismo experimento, pero ahora con el balanceo de datos, separando el mismo número de videos de clase 1 que 0, y nos dio mucho mejores resultados:

El aprendizaje que se obtuvo en este proyecto es claro: la percepción global de que, en los algoritmos de Machine Learning, como más datos/ejemplos demos al modelo mejor clasificará es una opinión sesgada. Aunque el sentido común nos diga que a más ejemplos mejor rendimiento en la clasificación, no es lo mismo un SVM que una Deep Neural Network, y es mucho más importante la calidad que la cantidad de estos datos.
La implementación se hizo en un servidor de Python, donde subimos el modelo ya entrenado. A partir de una sencilla interfaz gráfica, se puede subir subir un audio .mp3 o .wav con la moto que quieres analizar.

El audio que se suba será procesado, primero cortándolo en distintas partes de tamaño igual a 5 segundos, tal y como hicimos para nuestro dataset de entreno. Una vez hemos calculado el espectrograma de cada una de nuestras muestras de 5 segundos, realizamos la inferencia del modelo para cada una de las imágenes.
El modelo, por tanto, devolverá un vector con valores clase 0 o clase 1 para las N imágenes de entrada. Si está muy seguro de que el audio de entrada es una Yamaha, devolverá todo 1s, si piensa que no es una Yamaha, todo 0s. El porcentaje de confianza con el que se ha hecho esa predicción se calcula a partir del número de fragmentos que coinciden con la predicción mayoritaria, midiendo así la consistencia en las predicciones. Por ejemplo, si de un audio de entrada sacamos 4 fragmentos, y 3 de ellos los hemos detectado como Yamaha, estamos un 75% seguros de que el audio de entrada es una Yamaha.

Hasta aquí la parte de experimentación… Pero aún hay más que contaros, que seguro que os parecerá interesante. Si sois fans (como nosotros) de The Big Bang Theory, os acordaréis de un capítulo donde Sheldon Cooper se viste de Efecto Doppler, aunque todos lo confunden con una cebra. Este efecto surge del comportamiento electromagnético de una onda en producirse por un cuerpo en movimiento, como es el caso de las ambulancias.

Figura 13: Matriz Precision-Recall y F1 Score para datos balanceados
El aprendizaje que se obtuvo en este proyecto es claro: la percepción global de que, en los algoritmos de Machine Learning, como más datos/ejemplos demos al modelo mejor clasificará es una opinión sesgada. Aunque el sentido común nos diga que a más ejemplos mejor rendimiento en la clasificación, no es lo mismo un SVM que una Deep Neural Network, y es mucho más importante la calidad que la cantidad de estos datos.
La implementación se hizo en un servidor de Python, donde subimos el modelo ya entrenado. A partir de una sencilla interfaz gráfica, se puede subir subir un audio .mp3 o .wav con la moto que quieres analizar.

Figura 14: Entrada para archivo de audio en el servidor de Ideas Locas
El audio que se suba será procesado, primero cortándolo en distintas partes de tamaño igual a 5 segundos, tal y como hicimos para nuestro dataset de entreno. Una vez hemos calculado el espectrograma de cada una de nuestras muestras de 5 segundos, realizamos la inferencia del modelo para cada una de las imágenes.
El modelo, por tanto, devolverá un vector con valores clase 0 o clase 1 para las N imágenes de entrada. Si está muy seguro de que el audio de entrada es una Yamaha, devolverá todo 1s, si piensa que no es una Yamaha, todo 0s. El porcentaje de confianza con el que se ha hecho esa predicción se calcula a partir del número de fragmentos que coinciden con la predicción mayoritaria, midiendo así la consistencia en las predicciones. Por ejemplo, si de un audio de entrada sacamos 4 fragmentos, y 3 de ellos los hemos detectado como Yamaha, estamos un 75% seguros de que el audio de entrada es una Yamaha.

Figura 15: Porcentaje de confianza en la decisión tomada
Hasta aquí la parte de experimentación… Pero aún hay más que contaros, que seguro que os parecerá interesante. Si sois fans (como nosotros) de The Big Bang Theory, os acordaréis de un capítulo donde Sheldon Cooper se viste de Efecto Doppler, aunque todos lo confunden con una cebra. Este efecto surge del comportamiento electromagnético de una onda en producirse por un cuerpo en movimiento, como es el caso de las ambulancias.

Figura 16: Disfraz Efecto Doppler de Sheldon Cooper y explicación del efecto
Como bien se explica en las imágenes anteriores, un cuerpo en movimiento que se acerca hacia ti hará que el oyente perciba frecuencias más altas que para otro oyente donde el objeto se está alejando de él. Nos dimos cuenta durante la recopilación de datos de que era un factor que considerar, ya que los espectrogramas de las motos de gran cilindrada en movimiento daban espectrogramas muy distintos a los de, por ejemplo, una Vespa en parada, y no tenía nada que ver con el tipo de motocicleta sino de cómo se había grabado. E incluso, si te fijabas en las frecuencias percibidas antes y después de que pasara la moto, se podía apreciar el efecto Doppler que como buen ingeniero en telecomunicaciones me hizo especial ilusión.

Figura 17: Espectrograma motocicleta en movimiento y
presencia de efecto Doppler a medida que se aleja el emisor
Y hasta aquí este interesante y divertido experimento en el que hemos podido aprender desde los fundamentos de procesamiento de señal hasta la implementación con Deep Learning y SVM de un clasificador de sonidos a partir del espectrograma. Esperemos que os haya gustado.
¡Saludos!
Autores : Bruno Ibañez (@brunoaibanez) y Guillermo Peñarando Sánchez, del equipo de Ideas Locas CDCO de Telefónica.



















{kind=link}
{kind=link}
1 comentario:
Claro que eso es posible, yo tuve moto toda mí vida y podía reconocer su sonido en más de un 90% de exactitud. Es increíble como el oído y tu cerebro guardan esa información, es como el canto de los pájaros, ellos se reconocen o como los timbres de voz de los seres humanos.
Publicar un comentario